
9 Pieces of Dev Wisdom You Only Learn After Building Real Systems
Wisdom you will only gain once you are in production


Every engineer collects scars. The kind that don’t show up in your resume but live rent-free in your head every time you write a similar piece of code.
These nine lessons aren’t theoretical. Each one was learned inside a war room, a Slack thread during outage, or a post-mortem doc written in collective shame. If any of these sounds painfully familiar - you’re in good company.
Let’s get into them - with real examples.
The Coupling Rule
1) If two modules talk too much → merge them
Assume at one company, you had a billing module and a pricing module.
In theory, they were separate concerns. Clean architecture, nice diagrams, everyone clapped in the design meeting.
In reality? Every billing call needed pricing data. Every pricing change required a billing update. They were calling each other constantly - like a couple fighting but refusing to break up.
What life looked like every sprint
Pricing team deploys → billing breaks
Billing team deploys → pricing edge cases surface
Both teams stop and blame the interface contract
Everyone writes more tests. Nothing fundamentally changes.
One afternoon the team sat in a conference room and said the quiet part out loud: “These aren’t two modules. They’re two halves of one responsibility.”
We merged them into a single service. Now: fewer deploy issues, simpler tests, no circular dependencies, cleaner ownership.
Warning sign: If you're maintaining a shared interface document just so two modules don't break each other - the abstraction is lying to you.
Lesson: Chatter = coupling. If two parts can’t live without each other, don’t force the separation. Merge is not defeat - it’s clarity.
The Silence Rule
2) If they talk too little → introduce an event
The opposite problem showed up in another system.
The User Profile Service updated a user’s email address. Quietly. No ceremony, no announcements.
The Notification Service? It never heard a thing.
What users experienced
Changed email → no verification email sent to new address
No security alert about the email change
Old email (possibly compromised) no longer gets any notifications
Support tickets: “I never got any emails after updating my address”
You dug in and found the two modules had zero connection. No API call, no event, nothing. They just lived in separate repos doing their own thing, blissfully unaware of each other.
“The bug isn’t in either module - the bug is in the gap between them.”
You fixed it by publishing a simple event: user.email_updated.
Now the Notification Service subscribed and sent a verification. The Auth Service listened and invalidated sessions. The Audit Log captured the change. Everything downstream became consistent - without any module knowing about the others.
Lesson: Silence creates invisible bugs. If modules need awareness but not coupling - events fill the gap. The event bus is not overhead, it's connective tissue.
The Velocity Rule
3) If your logic changes often → use a rules engine
Assume you had a fraud detection system. Classic stuff - block suspicious transactions, flag risky merchants, apply region-specific policies.
Week 1: the logic fit in a single function. Clean, readable, nice.
Week 6: the product team wanted a new exception for enterprise clients.
Week 8: a region-specific override.
Week 10: a time-of-day condition.
By week 16, the function had 11 nested if blocks and nobody could read it without a whiteboard session.
The quarterly product meeting, every quarter
PM: “Small change - just add an exception for users over $50k spend”
Dev: “That’s a deploy. Full QA cycle. 2 weeks.”
PM: “For one condition?”
Dev: “...yes.”
In this case you had to switched to a rules engine. Business analysts wrote YAML-based rules, you loaded them dynamically at runtime, and 90% of changes stopped requiring a deploy entirely. QA tested rule files, not application builds.
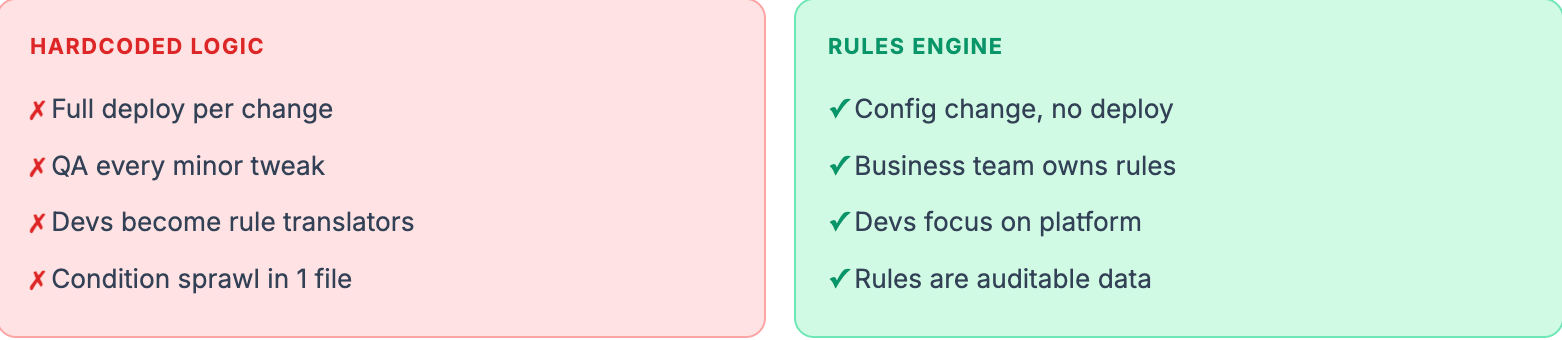
Lesson: Fast-changing logic doesn’t belong in code. Put it in data. Interpret it at runtime. Your future self will thank you at the next product planning meeting.
The Invisibility Rule
4) If your data changes often → use DB triggers carefully
Now we tracked customer loyalty points. Every transaction updated a running balance - inserts, updates, refunds, all of it.
Instead of recalculating the balance on every read, a clever dev set up a database trigger. It updated a denormalized points_balance column automatically on every transaction insert. Elegant. Fast. Very clever.
It worked beautifully… for three months.
Then someone added a business rule inside the trigger (a rule that should have lived in the application layer). Then another person added logging to the trigger. Then a third added a conditional.
"Why did this row update?" - "Oh, the trigger ran."
"Why didn't staging behave the same?" - "Different trigger version."
"Where is the trigger defined?" - silence.
Triggers are invisible code. They don’t show up in git blame. They don’t appear in your IDE search. Most devs don’t know they exist until something breaks in a way that makes no sense.
Good trigger use cases: Maintaining a last_updated_at timestamp. Enforcing a referential invariant. Logging raw inserts to an audit table. These are bookkeeping jobs - not business logic.
Lesson: Triggers are powerful - but invisible. Use them for bookkeeping and invariants, never for business rules. What lives in the DB, stays in the DB - and haunts future engineers.
The Cold Start Rule
5) If a cache miss hurts → precompute
If you have to build an analytics dashboard. Revenue per segment, top products, user cohort breakdowns. The kind that executives open first thing Monday morning, click frantically, and then send a message to engineering because it’s slow.
You cached it. But on a cache miss - a new day, a freshly deployed service, a cache eviction - the system had to recalculate everything from scratch across millions of rows. Every cache miss caused a CPU spike that slowed down every other service on the same host.
Monday 9:03 AM, every week
CFO opens dashboard → cold cache → 4-second spinner
Clicks “Refresh” (mistake) → triggers the calculation again
CPU spikes → API latency rises across the board
On-call engineer gets paged everytime
The fix wasn’t more Redis tuning. The fix was removing the heavy computation from the request path entirely. You have to run a background job every hour that precomputed all summaries and stored them. The dashboard read from a summary_snapshots table-— always pre-warmed, always fast.
Dashboard load time: 4 seconds → 100ms. The CFO stopped messaging engineering.
Lesson: If the fallback computation is expensive, move it out of the request path entirely. Caching defers work - precomputing eliminates it.
The Truth Rule
6) If staleness hurts → invalidate aggressively
E-commerce inventory is the opposite of the dashboard problem. Here, stale data doesn’t just slow things down - it breaks trust with the customer.
Your inventory cache had a 30-second TTL. Seemed reasonable. For most data, it is.
But inventory is not “most data.” Ten seconds of a stale cache meant a customer could see “Only 1 left!”, add the item to their cart, go through checkout, enter payment details, and then hit a hard wall: “Sorry, this item is no longer available.”
"We're a technology company losing revenue because of a 30-second cache."
- Someone's post-mortem, probably.
You tore out the TTL-based invalidation and replaced it with event-driven invalidation. Every purchase, restock, and cancellation published an inventory.changed event. The cache entry died the moment the stock did.
Caches are not slower databases. They are temporary agreements about what truth looks like. When the underlying truth changes, the agreement is void.
Lesson: In some systems, correctness beats speed. If the cost of a stale read is a user who can't trust your product - kill stale entries the moment the source of truth changes.
The Boundary Rule
7) If two services share a DB → they’re one service wearing two badges
I watched a team celebrate their “microservices migration.” They had split their monolith into a User Service and an Account Service. Two repos. Two deploy pipelines. Two Slack channels for on-call. Everyone felt modern.
Both services read and wrote to the same users table in the same database.
What happened every schema change
“We need to rename this column” → 2 PRs, 2 code reviews, 2 test suites
Migration runs → sometimes only one service gets the update
Rollback one → breaks the other
Neither team wants to own the migration; both blame the other
This isn’t a microservices architecture. It’s a distributed monolith - all the operational complexity of microservices, none of the data isolation benefits.
A real service boundary is defined by data ownership, not repository count. If you can’t change one service’s schema without modifying the other - they are one service. Merge them, or properly separate the data.
Lesson: Shared data = shared fate. You can have separate codebases and still be a monolith at the data layer. True microservices have strict data ownership - not just separate repos.
Before you read further
I write content like this in much more depth on Skilled Coder
150+ Handpicked DSA problems
Complete System Design Roadmap and 40+ HLD deep dives
Complete LLD topics with Practical classical problems approaches
Complete SQL + Data Engineering
End to End Java Interview Preparation
New Agentic AI foundation
Single Library. Yours forever → theskilledcoder.com
The Root Cause Rule
8) If “just one more index” fixes it → fix the query shape, not the hardware.
A dashboard at a fintech startup kept timing out. The on-call rotation for that feature was becoming someone’s full-time job.
The first engineer added an index. Fast again. Everyone cheered.
A month later, another slow query - another index. Then another. Then another. Six months in, the transactions table had 14 indexes. Write operations noticeably slowed down because every insert was now maintaining 14 separate B-trees.
“We didn’t have a query problem. We had an index addiction.”
You finally sat down and profiled the queries seriously. Here’s what you found:
The actual problems, none of which needed an index
Query joined on a non-selective UUID column (wrong join key)
Filtered on
status- only 3 possible values over 50M rowsSELECT *fetching 40 columns when the UI used 4Wildcard
LIKE '%keyword%'preventing index usage anyway
Now rewrote the queries. Dropped 9 of the 14 indexes. Performance improved. Write throughput improved.
How to actually fix it: Run EXPLAIN ANALYZE. Look for sequential scans on large tables. Fix the join key first. Then selectivity. Then column projection. Indexes are the last resort.
Lesson: Indexes are a bandaid. Query shape is the cure. Before adding another index, ask what the query is actually doing - and whether it should be doing it at all.
The Courage Rule
9) If every feature needs a flag → your release process is broken, not your code
You built a new onboarding flow. Clean design, better UX, everyone was proud of it. But to “reduce risk,” every step got wrapped in a feature flag.
The flag graveyard, after 6 weeks
show_new_onboarding_form- on in prod, off in staging (no one knows why)enable_new_analytics_events- on, but the dashboard reading them is offnew_validation_rules- off, because of a bug that was fixed 3 weeks agoenable_final_submission- nobody remembers what this was for
Toggling flags for each deploy was its own ceremony. QA had to test every flag combination. New engineers asked which flags were “safe” and got answers like: “...probably these ones?”
“We thought we were being safe. We were being afraid.”
The fix wasn’t better flag naming. It was fixing the conditions that made you afraid to ship without them. Once you had proper automated tests, proper staging parity, and gradual rollout infrastructure - you deleted most of the flags and never looked back.

Lesson: Feature flags are tools for confidence - not substitutes for it. If everything needs a flag, invest in your test coverage and your deploy pipeline. Ship with intent, not with hedges.
The best engineers aren’t the ones who never break things.
They’re the ones who break things once - and build something wiser in its place.
Every system scar is a lesson that no course could have taught you.
Thanks for reading :)