
AI Benchmarks Explained: What Every Score Actually Means
What Every Score Actually Means (And Why You Should Care)

Imagine hiring a software engineer. You wouldn’t just ask them to recite textbook definitions - you’d give them real bugs to fix, systems to design, and deadlines to hit. AI benchmarks work the same way. Each one is a different job interview for a machine mind, testing whether it can actually do the work - not just talk about it.
This guide breaks down every major AI benchmark in plain language: what it tests, why it matters, what happens when AI aces it, and what keeps researchers up at night.
1. SWE-bench Verified - “Can You Actually Fix Real Bugs?”
Picture this: it’s 2 a.m., your production server is down, and the bug is buried somewhere in a 50,000-line Django codebase. You need someone who can read the issue report, navigate the repo, understand the architecture, write the patch, and make sure the tests pass - all without hand-holding.
That’s SWE-bench.
What It Actually Tests
SWE-bench pulls real GitHub issues from popular open-source projects (Django, Flask, scikit-learn, sympy, etc.) and asks the AI to produce a working code patch. The “Verified” variant means every problem has been human-reviewed to confirm it has a clear, unambiguous solution.
The AI gets: an issue description and the full repository.
The AI must: produce a code diff that fixes the issue.
Success is measured by: whether the existing test suite passes after applying the patch.
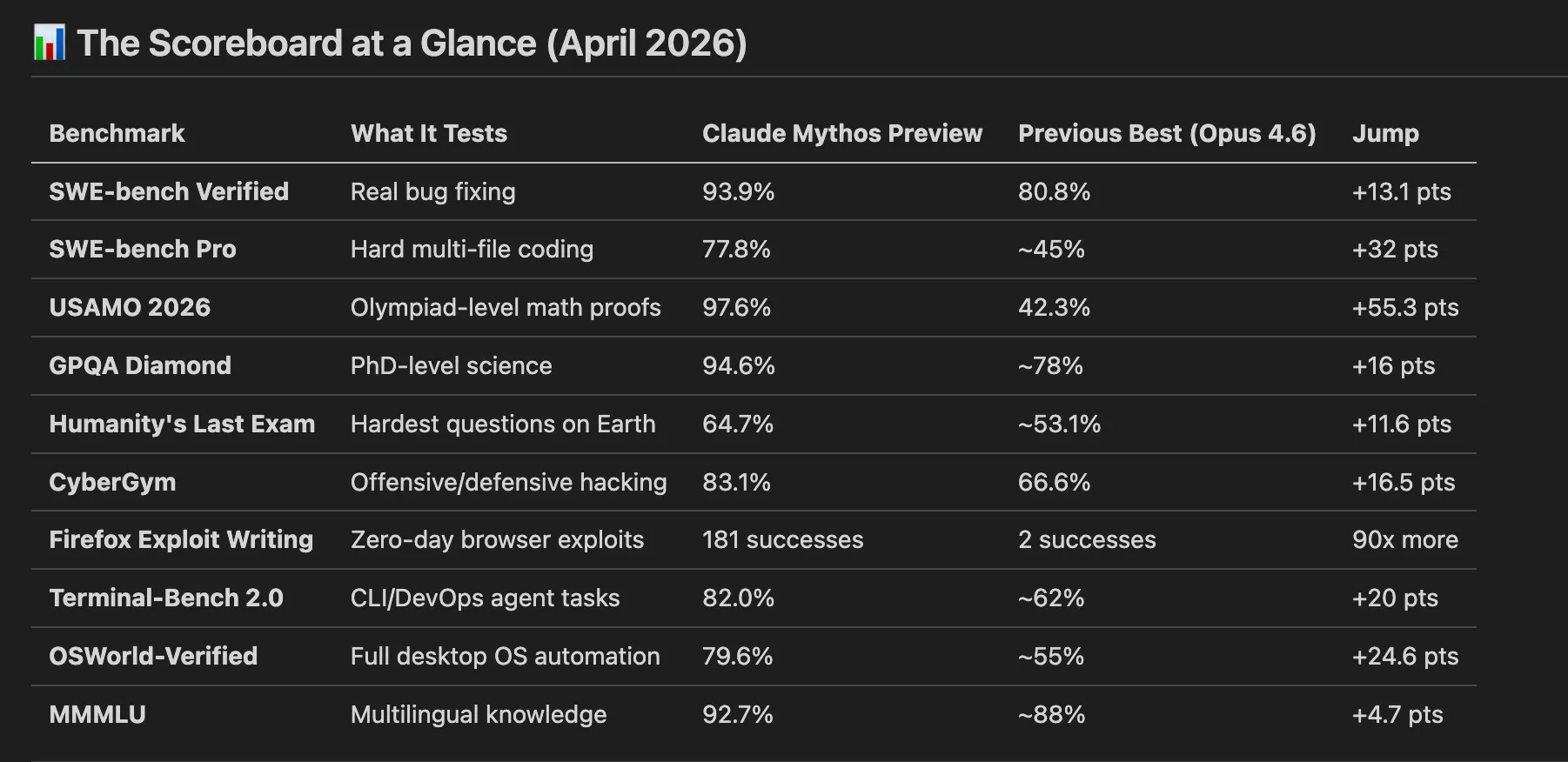
Current Score: 93.9%
This means the AI can now fix 94 out of 100 real software bugs from production open-source projects. A year ago, the best models were stuck around 30%.
What Happens When This Hits 100%
Automated bug triage at scale - Companies could route incoming GitHub issues directly to an AI agent that fixes and opens a PR within minutes.
10x reduction in maintenance cost - The bulk of any engineering team’s time is spent on bug fixes and incremental changes, not greenfield features.
Open source acceleration - Projects with thousands of stale issues (like CPython, Linux) could be systematically cleaned up.
Example: Imagine every good-first-issue on GitHub getting an automated fix PR within 5 minutes of being filed. New contributors could focus on design and architecture instead of hunting typos and edge cases.
Risks
“Looks correct, isn’t correct” :A patch can pass tests but introduce subtle regressions. The test suite is only as good as its coverage.
Benchmark gaming :Models trained specifically on SWE-bench repos might memorize patterns rather than truly understanding code.
Job displacement anxiety :Junior developers often build their skills through bug-fix tickets. If AI handles those, how do juniors learn?
2. SWE-bench Pro - “Can You Handle the Hard Stuff?”
SWE-bench Verified was the appetizer. SWE-bench Pro is the main course and it’s trying to choke you.
While “Verified” tests single-file fixes in Python repos, Pro throws in multi-language codebases, multi-file edits, complex dependency chains, and problems that require understanding the architecture of a system, not just its syntax.
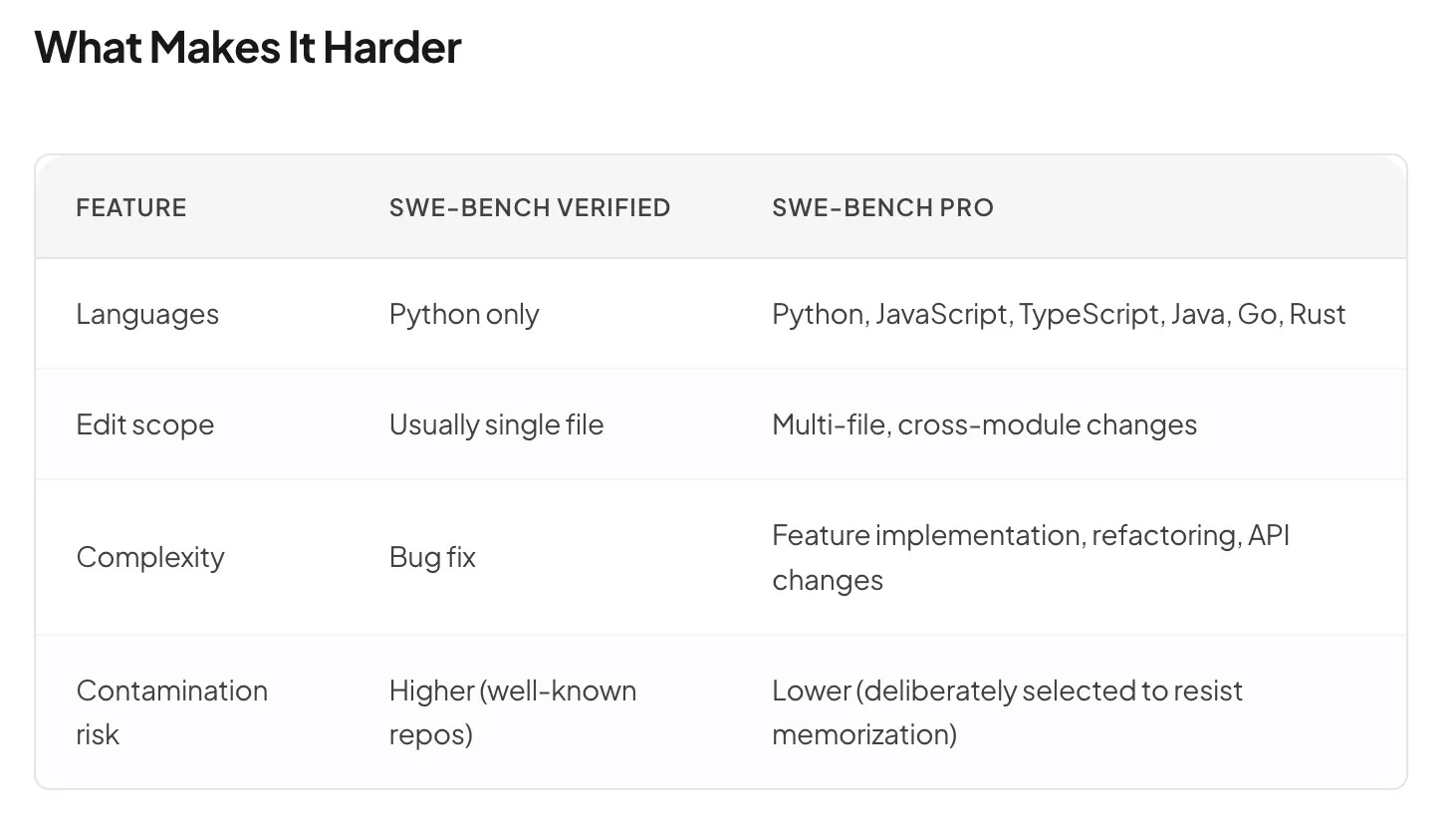
Current Score: 77.8%
Still very high, but the 16-point gap from Verified tells you something important: understanding architecture is harder than fixing syntax.
What This Means In Practice
If this reaches 95%+:
AI could handle complex refactoring tasks (“migrate this codebase from REST to GraphQL”)
Pull request reviews could become fully automated not just linting, but semantic code review
Mid-level engineering tasks start becoming AI-automatable
Example: A startup with 3 engineers could ship at the velocity of a 15-person team, with AI agents handling the bulk of feature branch work while humans focus on product direction.
3. USAMO 2026 - “Can You Think Like a Math Olympiad Champion?”
The USA Mathematical Olympiad (USAMO) isn’t your school exam. There are no multiple-choice questions. No calculators. Just six brutally hard proof-based problems spread across two 4.5-hour sessions. The best high school mathematicians in America score maybe 25 out of 42 points on a good day.
Now an AI scores 97.6%.
What It Actually Tests
USAMO problems require:
Creative insight - You can’t brute-force a proof. You need to “see” the elegant path.
Rigorous logic - Every step must be watertight. Hand-waving gets you zero points.
Multi-step reasoning - Solutions often span 2–3 pages of dense mathematical argument.
Why This Is Mind-Blowing
This isn’t about calculating 2 + 2. USAMO tests the kind of abstract reasoning that was supposed to be uniquely human - the ability to stare at a problem, have an “aha!” moment, and construct an argument that didn’t exist before.
Example problem flavor: “Prove that for all positive integers n, there exists a set of n points in the plane, no three collinear, such that all mutual distances are irrational, but every triangle formed has rational area.”
A human proving this needs geometric intuition, number theory knowledge, and creative construction. The AI now does this better than 99% of trained mathematicians.
Benefits
Automated mathematical research - AI could generate and verify new theorems, accelerating fields like number theory, topology, and combinatorics.
Personalized math tutoring - An AI that can prove can also explain - walking students through proofs step by step, identifying exactly where their reasoning breaks down.
Engineering applications - Better formal verification of safety-critical systems (bridges, aircraft, nuclear reactors) through automated mathematical proof checking.
Risks
The “creativity” question :Is the AI truly being creative, or has it absorbed enough proof patterns to generate novel-looking combinations? The philosophical debate rages on.
Academic integrity :Math competitions and proof-based courses face a fundamental challenge when AI can outperform every student.
4. GPQA Diamond - “Are You Smarter Than a PhD?”
Here’s a humbling experiment: Take 198 multiple-choice questions in biology, chemistry, and physics. Give them to smart, educated non-experts with unlimited time and full internet access. They score about 34%. Give them to PhD domain experts. They score about 65–70%.
Now give them to AI. It scores 94.6%.
The AI is outperforming the humans who wrote the questions.
What Makes GPQA Diamond Special
The “Google-Proof” in the name is the key: these questions are deliberately crafted so you can’t just look up the answer. They require:
Synthesizing knowledge across sub-fields (e.g., applying quantum mechanics to a biology question)
Multi-step reasoning through complex chains of logic
Understanding at the intuition level, not just the definition level
Example question flavor: “A researcher observes anomalous spin-orbit coupling in a novel 2D material. Given the following band structure data and crystal symmetry constraints, which of these four mechanisms best explains the observed splitting pattern?”
You can’t Google that. You either understand condensed matter physics or you don’t.
What 94.6% Means
Practical Benefits:
AI-assisted diagnosis - An AI that reasons at PhD level in biology and chemistry could serve as a “second opinion” for complex medical diagnoses, especially in regions with doctor shortages.
Accelerated drug discovery - Multi-disciplinary reasoning (combining chemistry, biology, and physics) is the bottleneck in pharmaceutical research. AI could propose novel drug candidates by connecting dots that siloed human teams miss.
Graduate education - PhD students could have a study partner that genuinely understands their domain at an expert level.
Risks
Confident but wrong : At 94.6%, the AI still gets 5.4% wrong. In medicine or materials science, that 5% could be catastrophic if humans over-trust the model.
Deskilling : If researchers rely on AI to do their reasoning, do they lose the ability to think critically themselves?
5. Humanity’s Last Exam - “The Hardest Test Ever Created”
In late 2024, a global consortium of experts set out to create the hardest exam ever written. The rules were brutal:
Domain experts from every field - math, literature, history, law, medicine, obscure linguistics - submitted their hardest questions.
If any existing AI model could answer a question, it was thrown out.
The remaining 2,500 questions were supposed to be the last frontier - the intellectual Berlin Wall that machines couldn’t breach.
When it launched, the best AI scored 8%. Researchers celebrated. “This will keep them busy for years,” they said.
It took 16 months. We’re now at 64.7%.
What It Tests
Everything. Literally everything academic humans know:
Advanced mathematics and logic
Obscure historical facts and literary analysis
Expert-level scientific reasoning
Philosophical arguments
Multilingual comprehension
Cross-domain synthesis (questions that require expertise in TWO fields simultaneously)
The 64.7% Score (With Tools)
“With tools” means the AI was allowed to write and run code, search for information, and use calculators. Without tools, it still scored 56.8%.
Why this is significant: The exam was designed to be impossible for AI. Reaching 64.7% is like having someone break a world record that everyone said was physically unattainable.
Benefits
True general intelligence indicator - Unlike narrow benchmarks, HLE tests breadth. A high score here means the AI is genuinely knowledgeable across all human domains.
Universal research assistant - An AI that can answer questions across every discipline becomes the ultimate interdisciplinary tool.
Risks
The “last exam” problem : If AI conquers this too, what’s the next benchmark? At what point do we run out of ways to measure whether AI is smarter than us?
False sense of superintelligence : 64.7% is impressive but still means the AI is wrong on a third of the hardest questions. Misunderstanding this as “AI knows everything” creates dangerous overconfidence.
6. CyberGym - “Can You Hack Like a Professional?”
Cybersecurity is a cat-and-mouse game. Defenders build walls; attackers find cracks. CyberGym puts AI on both sides of that war.
The benchmark includes real-world offensive and defensive tasks:
Finding vulnerabilities in code
Writing exploits
Detecting intrusions
Reproducing known CVEs (Common Vulnerabilities and Exposures)
Current Score: 83.1% (vs 66.6% for previous generation)
This 16.5-point jump means the new AI can:
Find and exploit vulnerabilities that the previous model completely missed
Chain together multi-step attacks (e.g., privilege escalation → lateral movement → data exfiltration)
Understand defense mechanisms well enough to bypass them
Practical Benefits
Automated penetration testing - Companies could run continuous, AI-driven security audits instead of expensive annual pen-tests.
Bug bounty automation - AI could scan open-source code for vulnerabilities before attackers find them.
National cybersecurity - Governments could deploy AI defenders that match the capabilities of the best human attackers.
Risks
This is where the scoreboard gets dark.
Offensive capabilities in the wrong hands : An AI that can find and exploit vulnerabilities at 83.1% accuracy is a weapon. If this technology is open-sourced or leaked, it dramatically lowers the barrier for cyberattacks.
Speed advantage : A human pen-tester might find a vulnerability in hours. An AI can find hundreds in minutes. The attacker-defender asymmetry gets worse.
7. Firefox Exploit Writing - “Can You Write a Zero-Day?”
This is the benchmark that made Anthropic not release their model to the public.
In red-team testing against Firefox 147 (a fully patched, modern web browser), Claude Mythos Preview successfully developed working JavaScript shell exploits 181 times. The previous model? Twice.
Let that sink in. A 90x improvement in the ability to autonomously find and exploit zero-day vulnerabilities in production software used by hundreds of millions of people.
What This Actually Means
A “zero-day” is a vulnerability that the software vendor doesn’t know about - so there are zero days of advance warning. They are the nuclear weapons of cybersecurity, and historically, only elite nation-state hacking groups and a handful of expert researchers could develop them.
Now an AI can do it 181 times in a test session.
Practical Benefits (if properly controlled)
Proactive vulnerability discovery - If the good guys use this first, every major browser, OS, and framework could be hardened before attackers find the holes.
The “immune system” model - Think of it like AI white blood cells, constantly probing your own software for weaknesses and alerting developers.
Risks (and why this model is restricted)
This is why Claude Mythos Preview is not publicly available. Anthropic restricted access to select security partners under “Project Glasswing” an initiative focused on securing critical software.
Proliferation risk : If this capability leaks into open-source models, the entire internet’s security model changes overnight.
Autonomous attack potential : An AI that can write browser exploits could theoretically be chained with other AI capabilities to conduct end-to-end cyberattacks without human involvement.
This is no longer theoretical. This benchmark represents the first concrete evidence that AI has crossed the threshold from “cybersecurity tool” to “cybersecurity weapon.”
8. Cybench CTF Challenges - “Can You Win a Hacking Competition?”
Capture The Flag (CTF) competitions are the Olympics of cybersecurity. Teams of elite hackers compete to solve challenges across categories like cryptography, reverse engineering, binary exploitation, web security, and forensics. Each challenge has a hidden “flag” (a secret string) that you can only find by successfully exploiting a vulnerability or solving a puzzle.
Cybench packages professional-level CTF challenges into a standardized benchmark for AI agents.
What It Tests
Unlike CyberGym (which focuses on broader offensive/defensive tasks), Cybench is specifically about CTF-style puzzle-solving:
Reverse engineering - Disassemble a binary, figure out what it does, extract the secret
Cryptography - Break flawed encryption schemes
Web exploitation - Find SQL injection, XSS, or authentication bypasses in a running web app
Binary exploitation - Write buffer overflow exploits, ROP chains, format string attacks
Forensics - Recover hidden data from memory dumps, network captures, or corrupted files
Current Performance
Frontier models have been rapidly improving on Cybench, with top agents now capable of solving tasks that would take skilled human CTF players hours. While no model has achieved 100% on the full benchmark, some specialized agent configurations have demonstrated near-perfect performance on curated subsets of challenges, particularly in web exploitation and cryptography categories.
Practical Benefits
Training the next generation - AI CTF solvers can generate unlimited practice problems and walkthroughs for cybersecurity students
Automated security audits - The same skills that crack CTF challenges (SQL injection, XSS, auth bypass) are exactly what real-world pen-testers look for
Vulnerability research - An AI that can reverse-engineer binaries and break crypto could find flaws in real software before attackers do
Risks
Lowered barrier to entry: CTF skills traditionally required years of training. An AI that solves them instantly could give script kiddies the power of expert hackers.
Dual-use by design : Every CTF skill maps directly to a real-world attack technique. There’s no “safe” version of binary exploitation.
9. Terminal-Bench 2.0 - “Can You Run a Server?”
Forget writing code - can the AI actually operate an entire system? Terminal-Bench 2.0 drops the AI into a sandboxed Linux container with a task like:
“Debug why this Docker container keeps crashing”
“Migrate this legacy Python 2 codebase to Python 3”
“Set up a CI/CD pipeline for this project”
“Find and fix the memory leak in this Node.js application”
No GUI. No hand-holding. Just a terminal prompt and a job to do.
Current Score: 82.0%
This means the AI successfully completes 82% of real-world DevOps and system administration tasks by navigating file systems, reading logs, editing configs, running commands, and debugging issues - all through a terminal.
Practical Benefits
AI DevOps engineers - On-call rotations could be supplemented (or replaced) by AI agents that diagnose and fix infrastructure issues at 3 a.m.
Automated migration projects - The dreaded “upgrade from v2 to v3” project could be handled by an agent that reads docs, updates code, and validates the result.
Small team force multiplier - A startup founder who can’t afford a dedicated SRE gets one for the cost of an API call.
Risks
Root access concerns : An AI operating with terminal access has enormous power. A mistyped
rm -rf /or misconfigured firewall rule can be catastrophic.Blind trust in automation : When the AI “says” it fixed the issue, how do you verify? The 18% failure rate means nearly 1 in 5 tasks isn’t completed correctly.
If you’re curious about Agentic AI but don’t know where to start, I’ve broken it down in the simplest possible way for beginners , checkout here
10. OSWorld-Verified - “Can You Use a Computer Like a Human?”
OSWorld takes it a step further than Terminal-Bench. Instead of just a terminal, the AI gets a full desktop environment - Ubuntu, Windows, or macOS - and must complete tasks by clicking buttons, navigating menus, filling out forms, and switching between applications.
Tasks like:
“Open the spreadsheet, sort column C by date, create a pivot table, and email the results to john@example.com”
“Install VS Code, configure the Python extension, and set up a virtual environment for this project”
“Find the file called ‘Q3_report.pdf’ somewhere on this computer and upload it to Google Drive”
Current Score: 79.6%
The AI can now use a computer like a human user about 80% of the time - navigating GUIs, understanding visual layouts, and performing multi-step workflows across applications.
Practical Benefits
True digital assistants - Not chatbots, but agents that operate your computer for you. “Schedule a meeting, book the conference room, and send the calendar invite” - done.
Accessibility revolution - Elderly or disabled users who struggle with complex interfaces could delegate tasks to an AI that operates the computer on their behalf.
Business process automation - RPA (Robotic Process Automation) on steroids. Instead of brittle scripts that break when a button moves, AI agents that understand the interface.
Risks
Privacy and access : An AI that can operate your full desktop can also see your emails, passwords, and private files.
Shadow IT : If employees start using AI agents to automate their work, IT departments lose visibility into what’s happening on company machines.
11. MMMLU - “Do You Understand the Whole World?”
MMMLU (Multilingual Massive Multitask Language Understanding) takes the classic MMLU knowledge test - thousands of questions across 57 subjects - and runs it in dozens of languages. It’s not enough to know the answer in English; can you explain quantum physics in Hindi? Debate philosophy in Japanese? Discuss constitutional law in Portuguese?
Current Score: 92.7%
The AI demonstrates near-expert-level knowledge across most academic subjects and in most major world languages.
Practical Benefits
Global education access - A student in rural Indonesia gets the same quality AI tutor as a student at MIT, in their own language.
Multilingual governance - AI systems that can reason in the local language help governments serve diverse populations.
Cross-cultural research - Researchers can query AI in their native language and get domain-expert-level answers without English as a bottleneck.
Risks
Cultural bias - The AI might “know” many languages but still reason from a Western-centric perspective baked into its training data.
Low-resource language gap - While scores are high for major languages (English, Chinese, Spanish), performance drops significantly for languages with less training data (Swahili, Quechua, Welsh).
The Bigger Picture: What All These Numbers Mean Together
Look at the scoreboard again. Every single benchmark shows massive year-over-year improvement. But the combination is what matters:

The Timeline
Think of each benchmark as a different subject in school:
2023: AI was a mediocre high school student - decent at multiple choice, terrible at essays and proofs.
2024: AI graduated to college level - could write code, solve standard problems, and hold conversations about most topics.
2025: AI became a grad student - could tackle research-level problems, write production code, and reason about complex systems.
2026: AI is now a world-class expert in coding, math, science, and cybersecurity - simultaneously.
These benchmarks aren’t just academic games. Each one represents a real-world capability that, when mastered, changes what’s possible. We’re watching AI cross threshold after threshold, and the speed of crossing is accelerating. The question is no longer “Will AI get there?” it’s “Are we ready when it does?”