
How Do You Design a System Where Most Writes Will Never Be Read?
The Art of Storing Data You’ll Probably Never Look At

Your app just logged this:
{
"timestamp": "2024-01-15T14:32:47.892Z",
"level": "INFO",
"service": "checkout",
"user_id": "u_8a7f3b",
"action": "page_view",
"page": "/products/shoes/running",
"duration_ms": 47,
"request_id": "req_9x8c7v6b"
}Will anyone ever read this log entry? Probably not.
But you still wrote it. Indexed it. Replicated it. Paid to store it. Along with the other 47 million logs your system generated today.
This is the paradox of write-mostly systems: You must capture everything while knowing almost nothing will be read. The question isn’t IF you should store it, but HOW you store data optimized for writing, not reading.
Write-Mostly Systems in the Wild
Application logs: 99.9% never viewed, critical for debugging that 0.1%
Audit trails: Written for compliance, read only during audits
Telemetry/metrics: Millions of data points, dashboards show aggregates
Security events: Stored for forensics, queried during incidents
IoT sensor data: Written constantly, analyzed in batches
Backup/archive: Written once, hopefully never restored
This chapter is about designing systems that optimize for write throughput, minimize storage costs, and still provide fast access to the tiny fraction of data you’ll actually need - without knowing which fraction that is.
The Fundamental Principle: Stop Paying for Reads You’ll Never Do
Every traditional database feature that speeds up reads has a cost at write time:
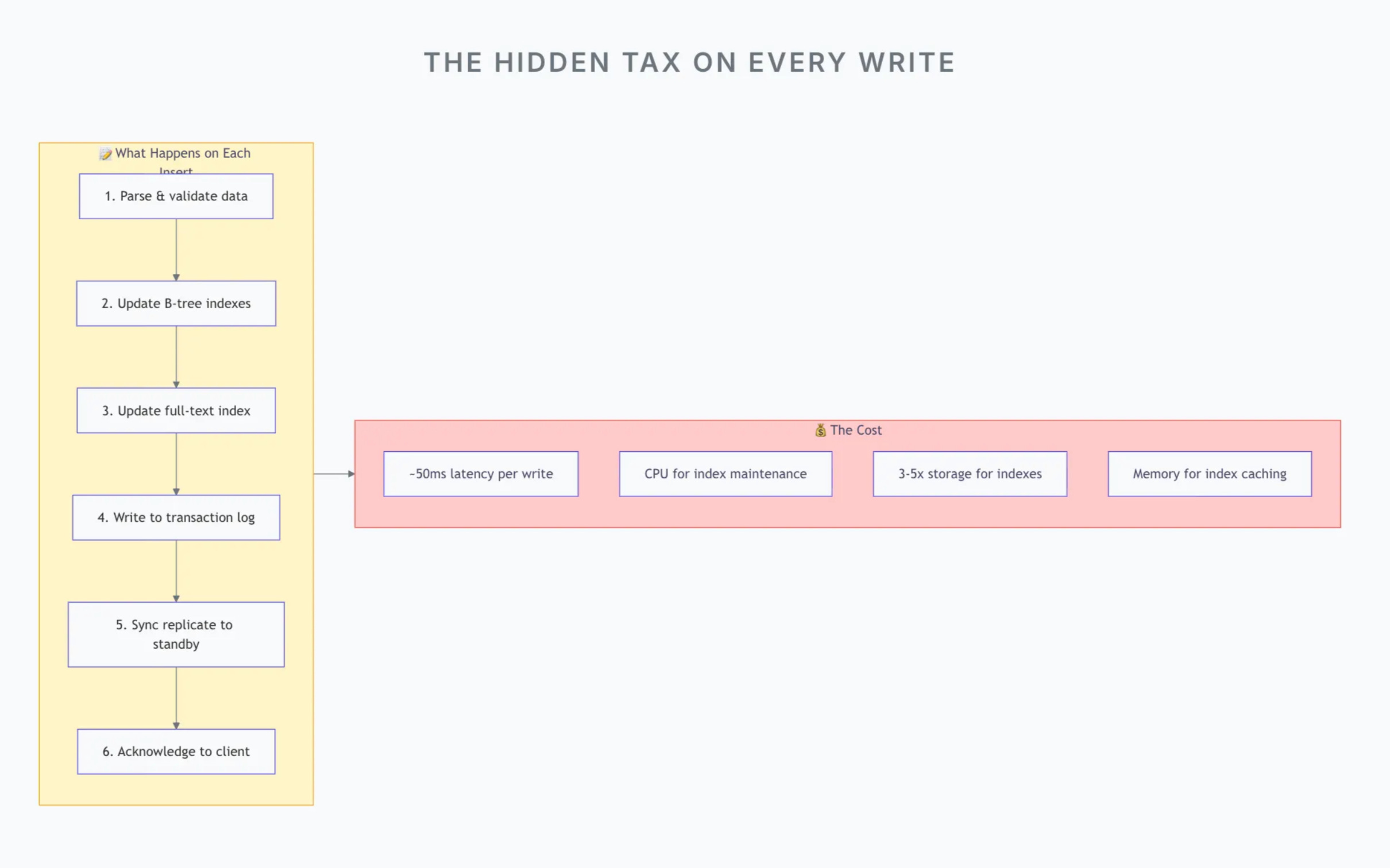
If you’re writing millions of records that will rarely be queried, you’re paying the “read optimization tax” millions of times for essentially zero benefit.
Why We Ignore Traditional Database Design Here
Traditional databases optimize for balanced workloads. They assume you’ll query your data. For write-mostly systems, we deliberately break several “best practices”:
No indexes at write time - We’ll build them later, if ever
Eventual consistency is fine - We don’t need immediate reads
Denormalization is expected - No joins means no foreign keys
Data loss is acceptable (sometimes) - Sampling reduces volume
Principle 1: Append-Only Beats Random Writes
The fastest way to write data is to never update, only append. This isn’t just an optimization - it’s a fundamental shift in how we think about storage.
Why Append-Only is 10–100x Faster
Traditional databases do random writes: when you insert a row, it may go anywhere in the file based on indexes and ordering. This means:
Disk seeks to find the right location
Page splits when blocks are full
Index rebalancing (B-tree rotations)
Transaction logging for each operation
Append-only storage does sequential writes: new data always goes at the end. This means:
No disk seeks (write head never moves backward)
No page management (just append to the end)
No index updates (we’re not indexing)
Batched logging (bulk commit)

Principle 2: Store by Column, Not by Row
This is perhaps the most counterintuitive principle. Why would storing data in columns instead of rows make such a difference for write-mostly systems?
The Compression Advantage
In row-based storage, each row contains mixed data types: timestamps, strings, numbers, booleans. Mixed data compresses poorly.
In columnar storage, each column contains the same type of data. And here’s the key insight: log data is highly repetitive within columns.

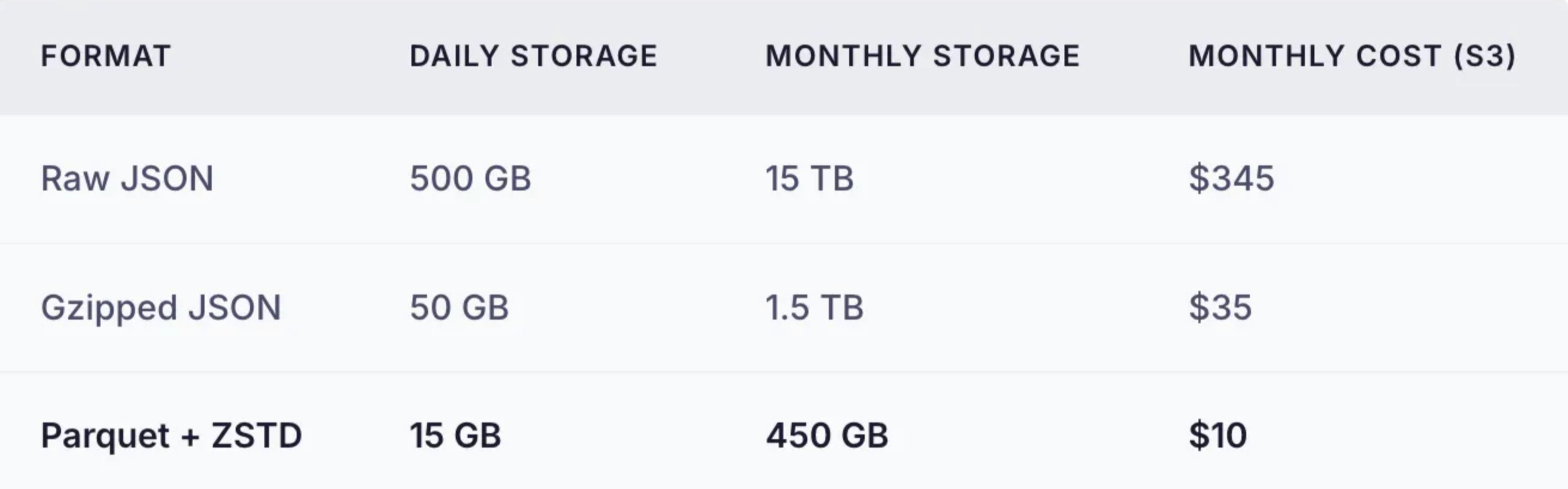
Result: Columnar formats like Parquet achieve 10–50x compression on log data. What would be 500GB in JSON becomes 15–50GB in Parquet.
Why This Matters for Costs
At scale, storage dominates costs. Consider 1 billion logs per day:
Principle 3: Data Value Decays Over Time
Here’s a truth about write-mostly data: its value decreases exponentially with age. Today’s logs are critical for debugging a live issue. Last month’s logs are useful for trend analysis. Last year’s logs exist only for compliance.
Yet most systems store all data the same way, paying hot-storage prices for data that’s essentially frozen.
Tiered Storage: Match Cost to Value
The principle is simple: move data to cheaper storage as it ages. Accept slower query times for data that’s rarely queried.
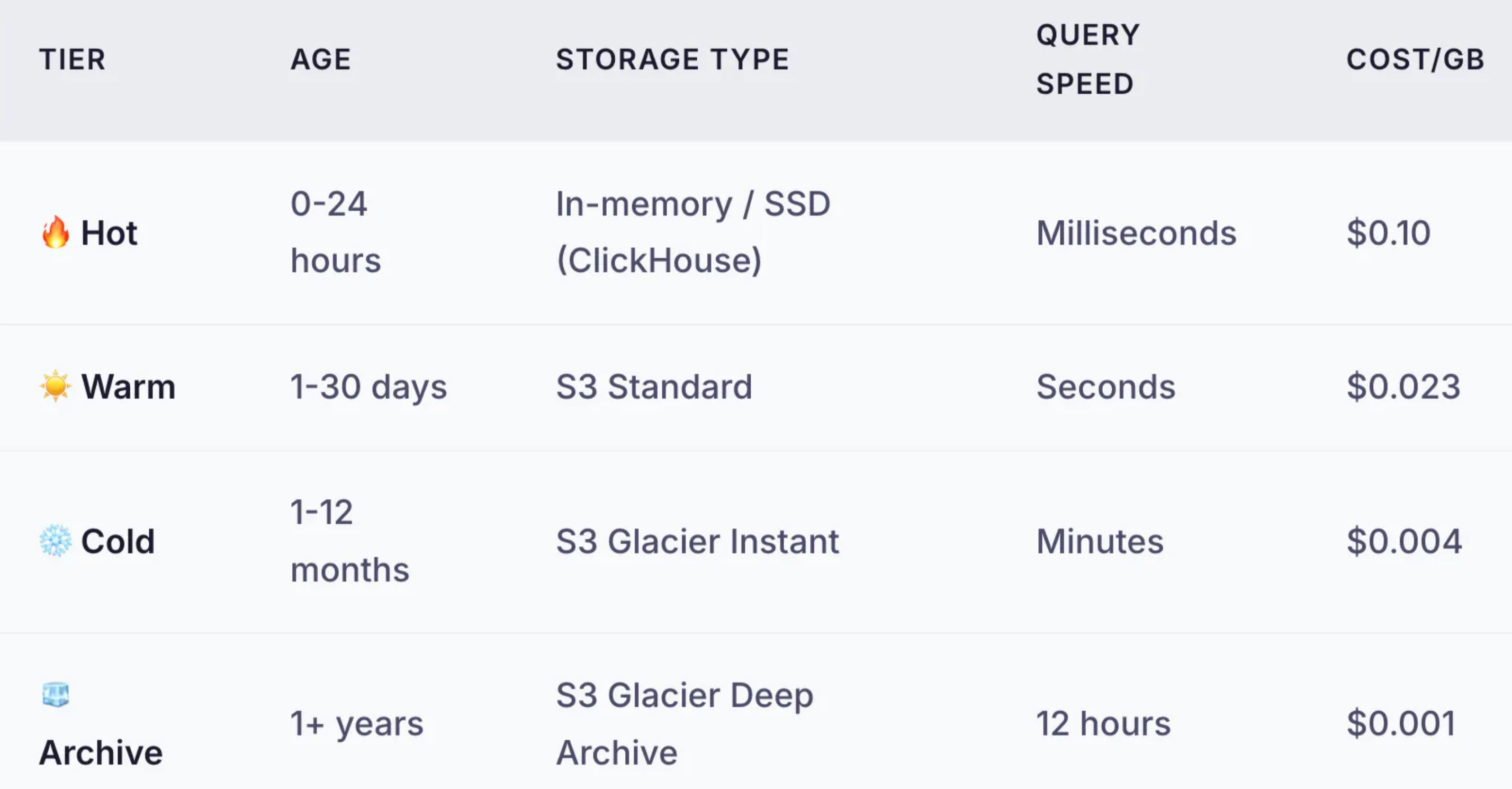
The Hidden Cost: Retrieval Fees
Cold storage is cheap to store but expensive to retrieve. Before archiving:
Glacier Instant: $0.03/GB retrieval
Deep Archive: $0.02/GB retrieval + 12-hour wait
Design implication: If you expect frequent ad-hoc queries on historical data, cold storage may cost more than warm storage. Do the math for YOUR access patterns.
Principle 4: Index Later, Not Sooner
Traditional databases index at write time because they assume you’ll query immediately. For write-mostly systems, this is backwards.
The Lazy Indexing Philosophy
Don’t index what you won’t search. Since 99% of your data won’t be queried, indexing 99% is waste. Instead:
Write everything unindexed — Pure append, maximum speed
Index only high-value data — Errors, anomalies, specific transactions
Build indexes on-demand — When a query pattern emerges, create the index
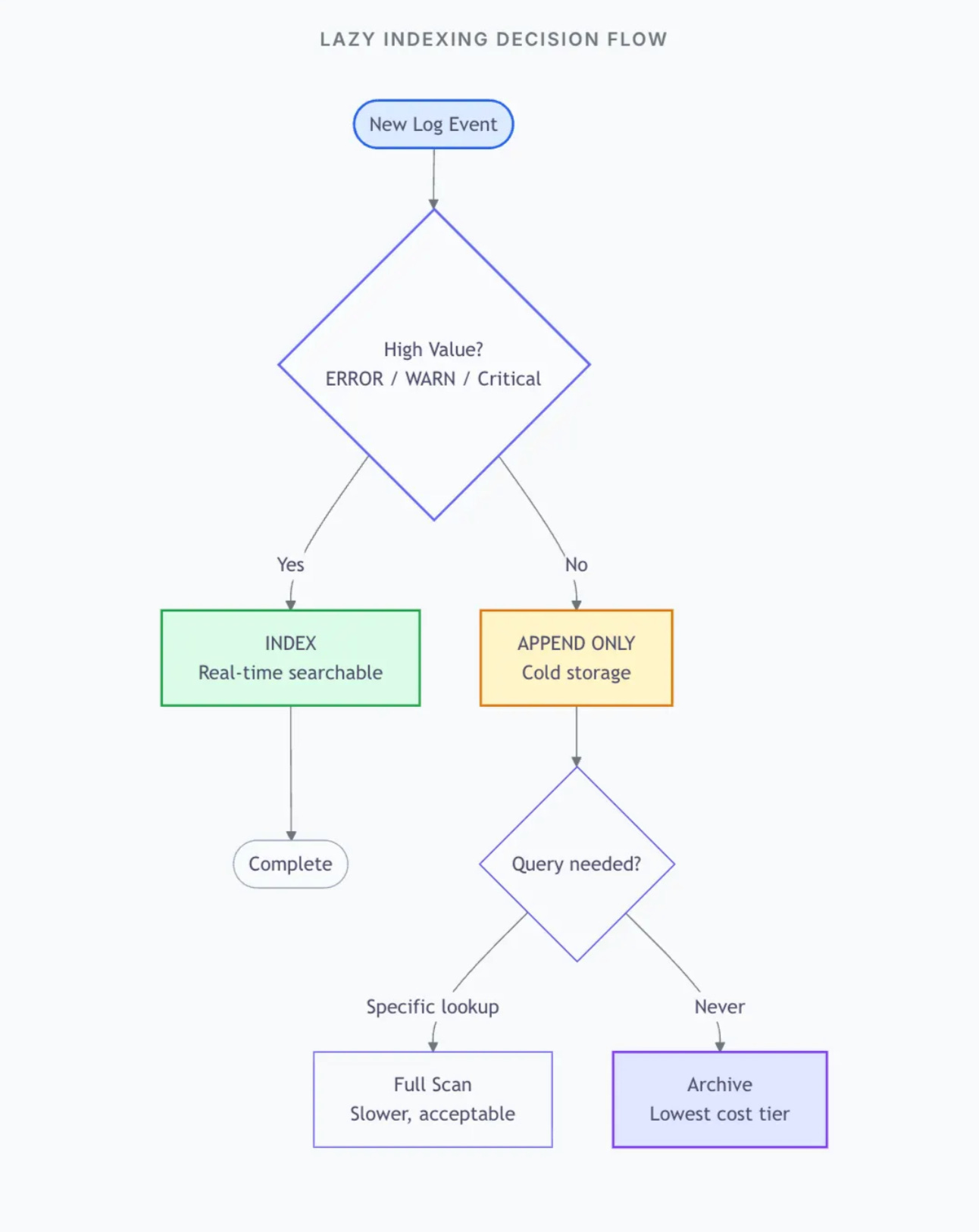
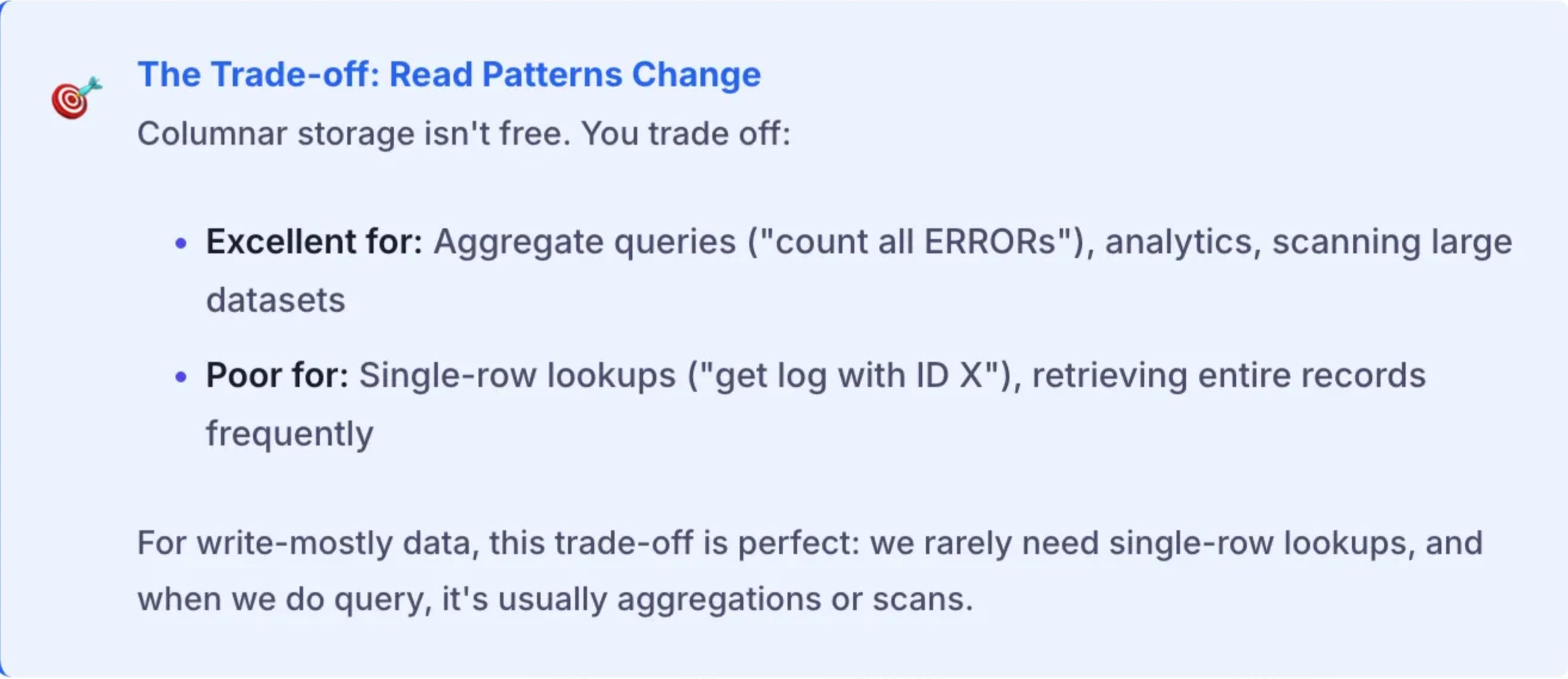
Why this works: Modern columnar formats (Parquet) are surprisingly fast to scan. Querying 1 billion rows in a well-partitioned columnar dataset takes seconds, not hours. For rare queries, scanning beats the cost of maintaining indexes.
Principle 5: Accept That Some Data Can Be Lost
This is the most controversial principle. Traditional systems treat every record as sacred. But for many write-mostly use cases, statistical accuracy matters more than individual records.
When Sampling Makes Sense
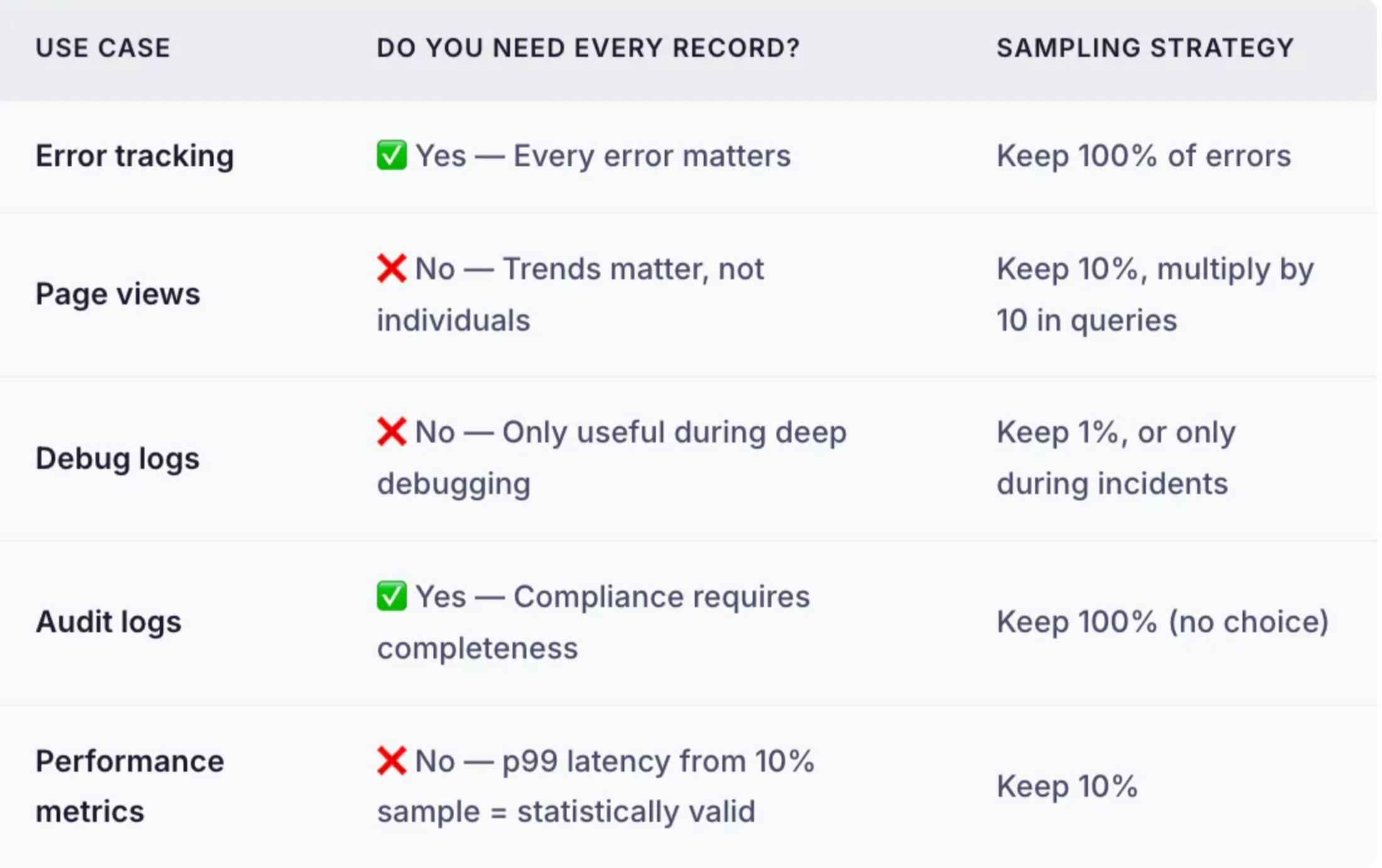
A 10% sample of 100 million events (10 million rows) gives you statistically valid results for almost any aggregate query. You save 90% of storage and processing costs.

Related (Before you read further)
This article scratched the surface. The real interview goes 10 levels deeper.
How do you handle hot partitions?
What if the cache goes down during a spike?
How do you handle compliance requirements?
You don’t need 10 scattered resources anymore to prepare.
I’ve put HLD, LLD, DSA, Java, DBMS + real system-design scenario like this article plus real system-design questions broken down the way they’re actually asked in interviews.
Putting It Together: The Write-Mostly Architecture
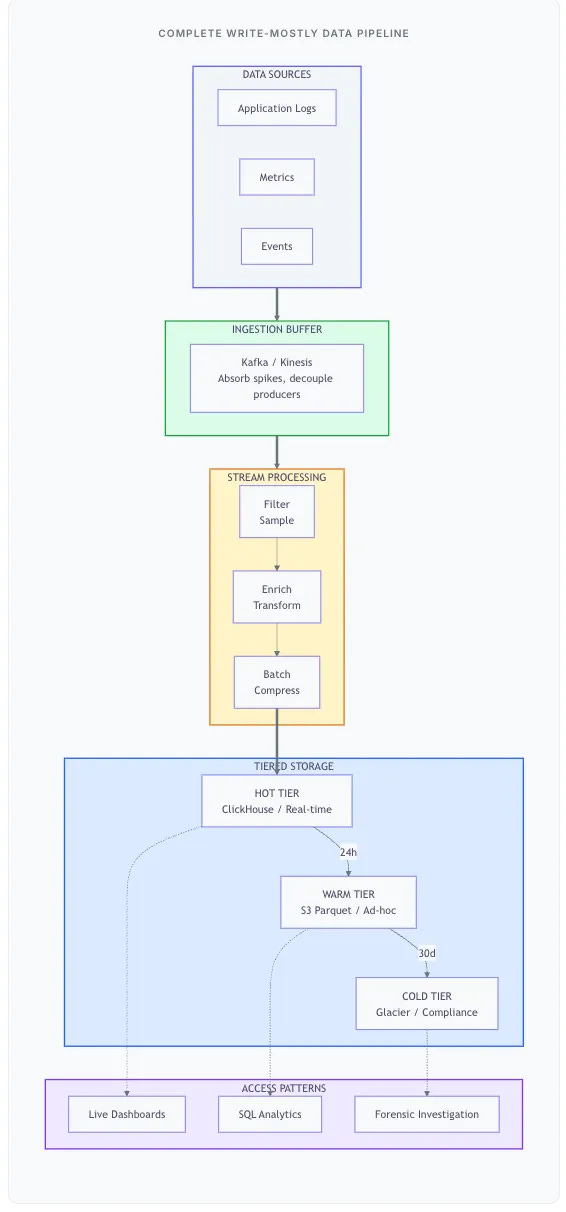
Case: When NOT to Use These Patterns
Don’t Apply Write-Mostly Patterns When:
You need immediate reads: User activity feeds, real-time analytics where users see their own data
Data requires updates: Status tracking, state machines, records that change over time
Query patterns are unpredictable: BI tools where users slice data in arbitrary ways
Consistency matters: Financial ledgers, inventory counts, anything where “eventually consistent” isn’t acceptable
What’s Next?
This problem can have variety of follow up questions
How do you query data across tiers?
What if you need to find a specific log entry?
How do you handle compliance requirements?
How do you decide retention periods?
We’ll cover similar real-world scenarios in upcoming articles or resource mentioned above.
building anything new right now?