
How Do You Design a System Where Reads Are Cheap But Writes Are Expensive?
The Art of Trading Write Complexity for Read Speed

Taylor Swift posts a single tweet: “New album at midnight”
That’s one write. One row inserted.
Within 30 seconds, 90 million followers need to see it in their timeline. That’s 90 million reads. For every single tweet.
When reads outnumber writes 1000:1, you can’t afford to compute anything at read time. The answer must already be waiting.
This chapter is about systems where you intentionally make writes slow and expensive so that reads become blazingly fast.
The economics are simple: if you read 1000x more than you write, spend 1000x more effort on the write.
First Attempts (and Why They Don’t Scale)
Attempt 1: Query at Read Time
-- Get user’s feed: JOIN everything at read time
SELECT posts.*
FROM posts
JOIN follows ON posts.author_id = follows.following_id
WHERE follows.follower_id = :user_id
ORDER BY posts.created_at DESC
LIMIT 50;Why it seems right:
Normalized data - no duplication
Always fresh - up to the second
Simple to understand
Why it fails at scale:
Massive JOINs: User follows 500 people × 100 posts each = scanning 50,000 rows
Repeated work: 10 users follow the same celebrity? Same computation 10 times
Read latency: 200ms+ per request when database is under load
Database meltdown: Can’t scale reads without replication lag issues
Attempt 2: Add a Cache
def get_feed(user_id):
cached = redis.get(f”feed:{user_id}”)
if cached:
return cached
# Cache miss - do the expensive query
feed = expensive_feed_query(user_id)
redis.setex(f”feed:{user_id}”, 300, feed) # 5 min TTL
return feedWhy it fails:
Cache stampede: When cache expires, 1000 users hit DB simultaneously
Stale data: New posts don’t appear for 5 minutes
Cold start: New users or cache eviction = slow first load
The underlying problem persists: Still doing the expensive query, just less often
The Cache is a Band-aid : Caching a slow query doesn’t fix the query. It just hides the problem… until the cache misses. The real solution is to never run the slow query at all.
The Patterns That Actually Work
Pattern 1: Fan-Out on Write
Instead of computing the feed at read time, push posts to followers at write time.
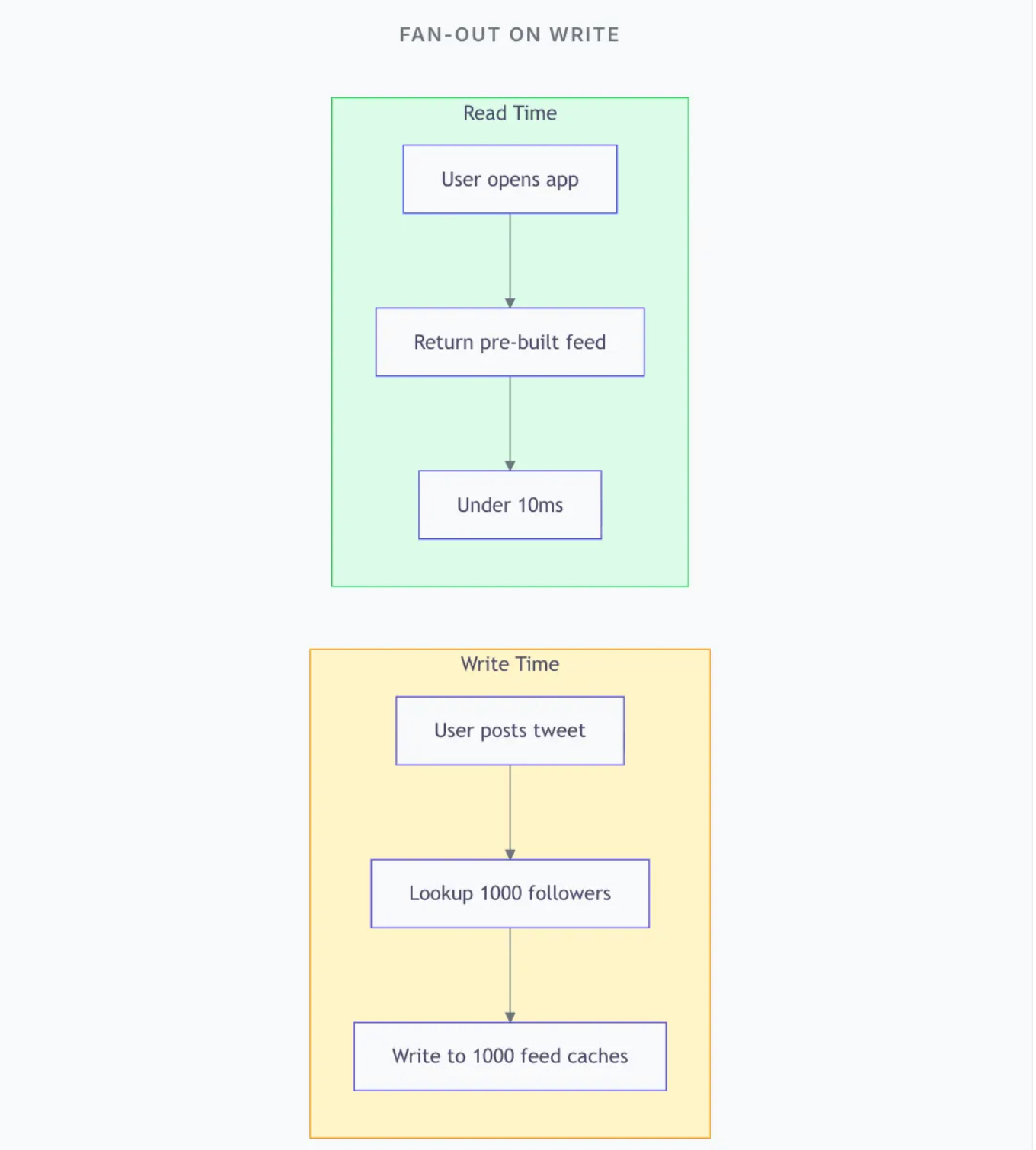
Trade-offs:

Pattern 2: Hybrid Fan-Out (The Twitter Solution)
For celebrities with millions of followers, pure fan-out is too expensive. Solution: fan-out for regular users, pull for celebrities.
def post_tweet(author_id, content):
tweet = db.insert(author_id=author_id, content=content)
follower_count = get_follower_count(author_id)
if follower_count < 10000: # Regular user
# Fan out to all followers
for follower_id in get_followers(author_id):
redis.lpush(f”feed:{follower_id}”, tweet.id)
else: # Celebrity - don’t fan out
# Just mark the tweet as from a celebrity
redis.sadd(”celebrity_tweets”, tweet.id)
def get_feed(user_id):
# 1. Get pre-built feed (from regular users)
feed = redis.lrange(f”feed:{user_id}”, 0, 50)
# 2. Merge in celebrity tweets (computed at read time)
celebrity_ids = get_followed_celebrities(user_id)
for celeb_id in celebrity_ids:
recent_tweets = get_recent_tweets(celeb_id)
feed = merge_and_sort(feed, recent_tweets)
return feed[:50]Why this works: 99% of users have < 10K followers. Fan-out handles them. The 1% of celebrities require a small read-time merge, which is acceptable.
Pattern 3: Denormalization
Store data redundantly so reads don’t require JOINs.
// Normalized: Requires JOIN to get author name
{
“post_id”: 123,
“author_id”: 456,
“content”: “Hello world”
}
// Denormalized: Everything needed is in one place
{
“post_id”: 123,
“author_id”: 456,
“author_name”: “Taylor Swift”,
“author_avatar”: “https://...”,
“author_verified”: true,
“content”: “Hello world”,
“like_count”: 47000000,
“reply_count”: 890000
}The cost: When Taylor changes her avatar, you update millions of posts.
The benefit: Every read is a single key lookup. No JOINs. Ever.
When to Denormalize
Data is read 100x more than written
The denormalized fields rarely change (names, avatars)
Read latency is critical
You can tolerate eventual consistency (old avatar for a few minutes)
Pattern 4: Materialized Views
Pre-compute and store query results. Update them when underlying data changes.
Use cases:
Dashboard aggregations (daily sales, weekly signups)
Leaderboards (top sellers, trending content)
Recommendation scores (pre-computed similarity)
-- Create a materialized view of product stats
CREATE MATERIALIZED VIEW product_stats AS
SELECT
product_id,
COUNT(*) AS review_count,
AVG(rating) AS avg_rating,
SUM(helpful_votes) AS total_helpful
FROM reviews
GROUP BY product_id;
-- Read: instant (no aggregation)
SELECT * FROM product_stats WHERE product_id = 123;
-- Refresh periodically or on trigger
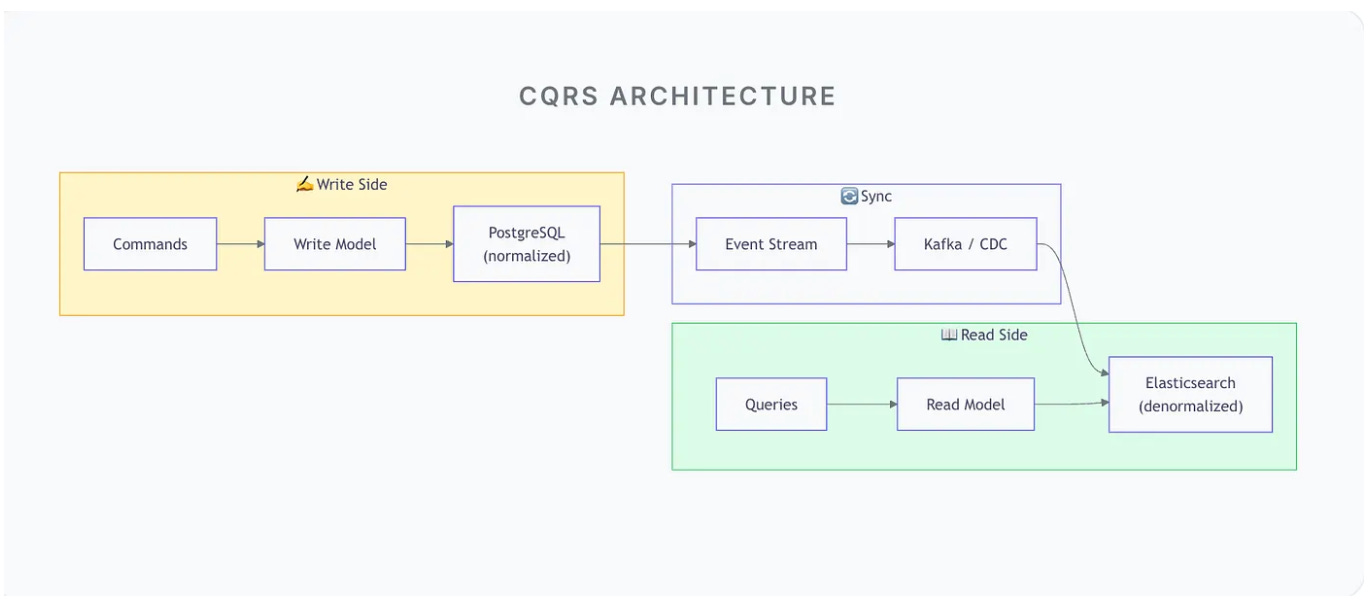
REFRESH MATERIALIZED VIEW product_stats;Pattern 5: CQRS (Command Query Responsibility Segregation)
Separate the write model from the read model entirely. Two different databases, optimized for their specific purpose. (image in header)

The key insight: The read model is a projection. It can be deleted and rebuilt from the write model anytime. This frees you to optimize it purely for reads.
Architecture: Putting It Together
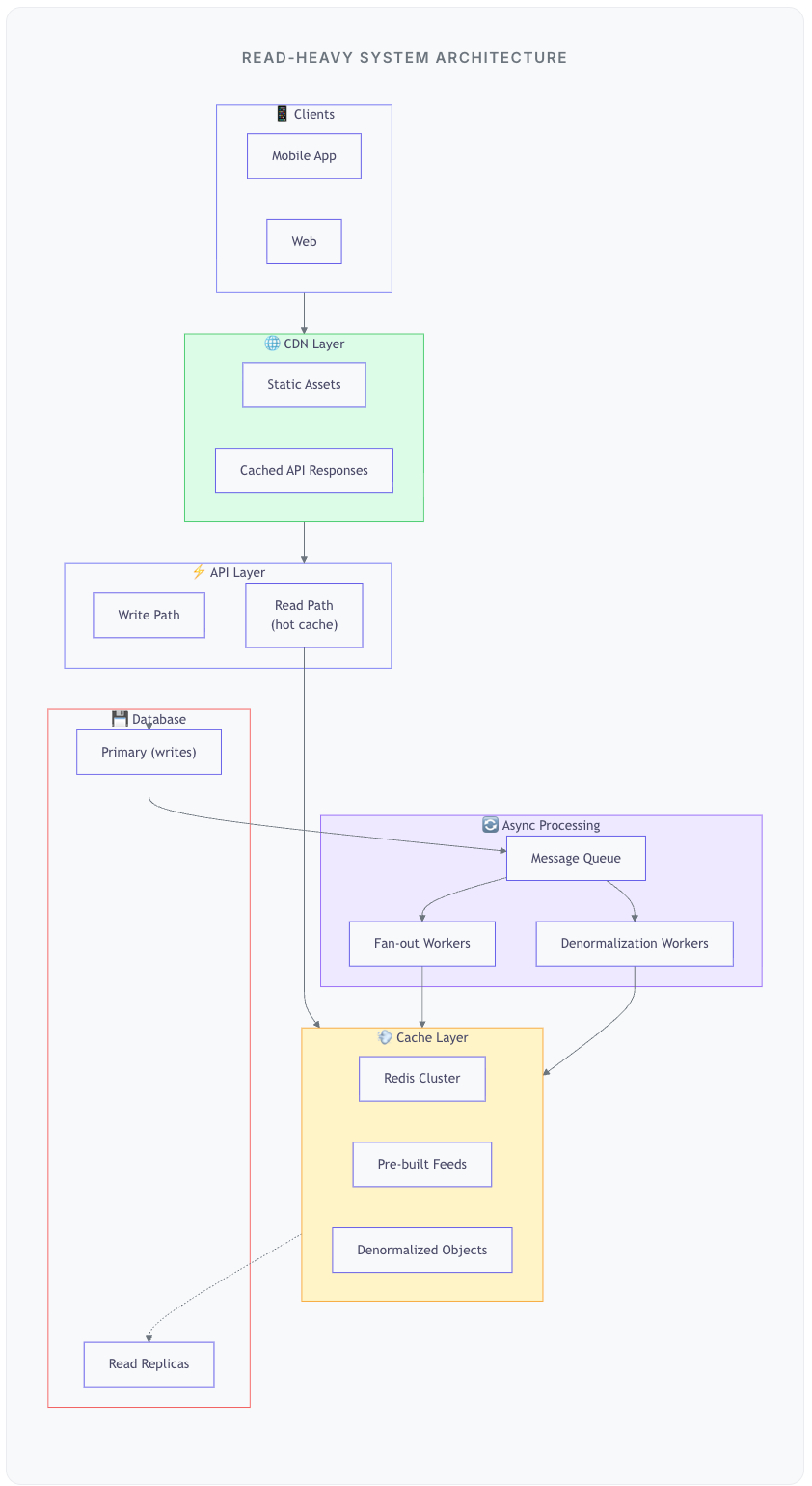
Data Flow: Write Path
User creates a post → write to primary database
Publish event to message queue
Fan-out worker: push to followers’ feed caches
Denormalization worker: update cached objects with new data
Data Flow: Read Path
User opens app → hit CDN for static content
API request → check Redis cache first
Cache hit (99% of time) → return immediately
Cache miss → read from replica, populate cache, return
Interview Pivot (How to Explain It)
If asked:
“How do you design a system where reads are cheap but writes are expensive?”
“The core principle is to move computation from read time to write time. If data is read 1000x for every write, I should do the expensive work once during the write, not 1000 times during reads.
For a feed system, I’d use fan-out on write. When a user posts, I push the post ID to every follower’s pre-built feed list in Redis. Reads become a simple list retrieval - O(1) instead of complex JOINs.
For celebrities with millions of followers, I’d use hybrid fan-out: push for regular users, pull for celebrities. We merge celebrity tweets at read time, which is acceptable for the small percentage of celebrity follows.
I’d also denormalize aggressively. Store author name and avatar with every post so reads don’t require JOINs. Yes, updating a user’s avatar means updating millions of posts, but that’s a background job - it doesn’t affect read latency.
For complex aggregations, I’d use materialized views or CQRS - separate read and write models entirely. The read model is denormalized and optimized purely for query patterns. It’s eventually consistent with the write model, but for most use cases that’s fine.”
What’s Next?
Every fast read is backed by expensive writes. There’s no magic - just a choice of when to pay the cost.
For read-heavy systems, pay at write time. Pre-compute feeds, denormalize data, maintain materialized views. Your writes become complex, but your reads become trivial. And at 1000:1 read/write ratio, that’s exactly the trade you want.
Read-heavy systems lead to deeper questions:
How do you handle a user unfollowing someone?
What if the write model and read model get out of sync?
How do you handle a new user with no pre-built feed?
How much storage does fan-out actually use?
Related
This article scratched the surface. The real interview goes 10 levels deeper.
How do you handle hot partitions?
What if the cache goes down during a spike?
How do you avoid counting the same view twice?
I’ve written an ebook that prepares you for all of it. (In detail with follow ups)
35 real problems. The patterns that solve them. The follow-ups you’ll actually face. The principles behind solving problems at scale, not just the final answers.