
How to Design a Tweet Scheduler System (That Scales to Millions)
The Backend Behind Scheduled Tweets

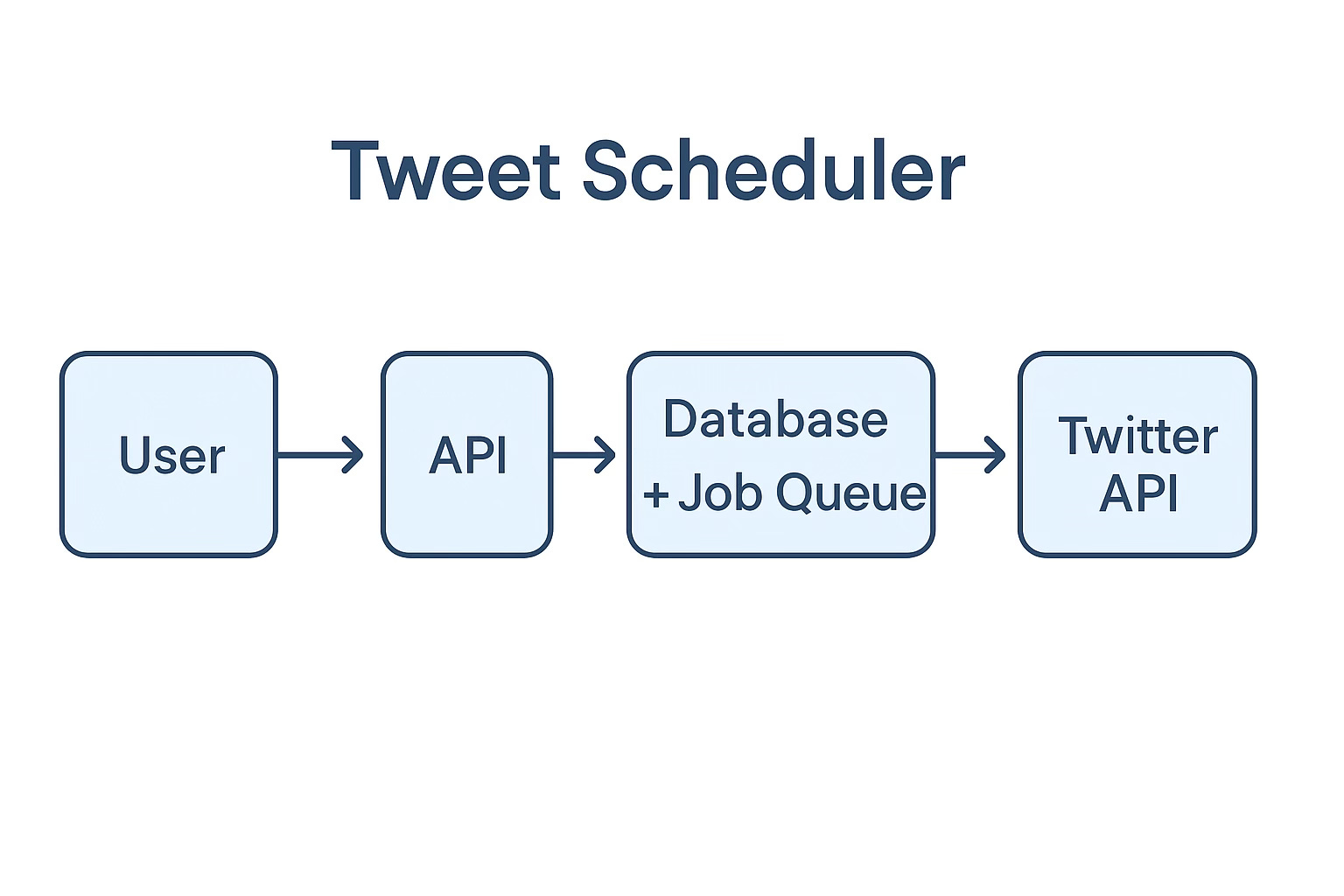
Scheduling tweets might sound like a simple feature - but designing a system that can reliably post millions of tweets at the exact scheduled minute (or second) is anything but.
In this article, we’ll break down how to architect a scalable, distributed Tweet Scheduler system that handles high throughput and ensures reliability.
The same principles apply to scheduling systems across other domains - newsletters, SMS, emails, or even push notifications.
Functional Requirements
User can schedule a tweet for a future time (down to the minute or second).
Tweet is automatically posted at the scheduled time.
User can view, edit, or delete scheduled tweets.
Supports authentication and authorization (via Twitter OAuth).
Should reliably retry in case posting fails.
Users can schedule:
Single tweets
Threads (multi-tweet posts)
Media attachments (images, videos)
Real-time status tracking of scheduled tweets (e.g., success, failed, pending).
Non-Functional Requirements
Scalability
Support millions of users scheduling tweets.
Handle thousands of scheduled posts per minute.
Precision
Tweets must go out at the exact scheduled time (± a few seconds max).
High Availability
No single point of failure.
Fault Tolerance
If a job fails (e.g., Twitter API is down), it should retry.
If retries fail, move to Dead Letter Queue and log the error.
Security
Securely store and manage user tokens (OAuth secrets).
Observability
Monitor job success/failure, posting lag, queue depth, and tweet delivery metrics.
Extensibility
Easy to add support for other platforms (e.g., LinkedIn, Facebook).
Challenges in Designing This System
Precise Timing : Tweets must go out exactly at the scheduled time - not early, not late.
High Scale : Handling millions of scheduled tweets daily, possibly thousands per second.
Retry Mechanism : If posting fails (e.g., network issues or API downtime), the system should retry safely.
Secure Token Handling
OAuth tokens must be stored and used securely to post on behalf of users.Edits & Deletions : Users might update or delete scheduled tweets before they are posted - system should handle that cleanly.
Distributed Processing : Workload must be spread across multiple workers without duplicate posting.
Clock Synchronization : Servers must have accurate, synced clocks to avoid time-drift issues.
Monitoring & Alerts : Failures, delays, and retries need to be tracked, logged, and alerted on.
Global Delivery : Users are worldwide - system needs to post reliably across time zones and regions.
High-Level Overview
User schedules a tweet via frontend → API → stored in DB.
Tweet is enqueued into a time-partitioned job queue based on its scheduled time.
At the scheduled time, distributed workers pick up the due jobs.
Each worker posts the tweet to Twitter using OAuth token.
On success, the tweet is marked as posted. On failure, it’s retried or sent to a Dead Letter Queue.
Monitoring tracks delivery status, failures, delays, and retries.
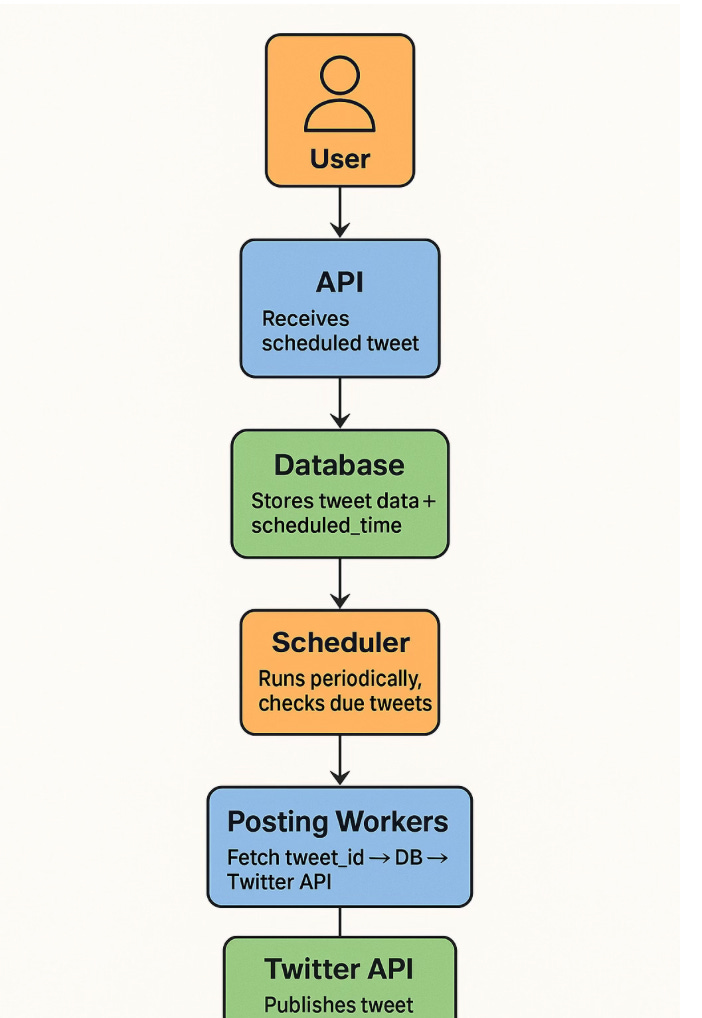
End-to-End Flow
Imagine 10 million users.
Each user can schedule tweets at arbitrary future times.
At 12:45 PM, the system may need to post 15,000 tweets scheduled by different users.
Now: how do you architect for this reality?
1. User Schedules a Tweet
User logs in with Twitter OAuth.
Frontend calls:
POST /schedule-tweet
Body: { content, scheduled_time, media_url, thread_id (optional) }Backend validates:
Auth token is valid.
Tweet format is within Twitter limits.
scheduled_timeis in the future.
2. Store in Database
Save tweet in scheduled_tweets table:
CREATE TABLE scheduled_tweets (
tweet_id UUID PRIMARY KEY,
user_id UUID,
content TEXT,
scheduled_time TIMESTAMP,
status ENUM('scheduled', 'posted', 'cancelled', 'failed'),
retry_count INT,
media_urls TEXT[], -- array of pre-uploaded media URLs
media_ids TEXT[], -- Twitter media_ids (after upload)
thread_id UUID, -- optional
created_at TIMESTAMP,
updated_at TIMESTAMP
);Indexed on
scheduled_timeto support time-based pullsuser_idis also indexed for UI display and user historymedia_urlsstore S3/CDN links (e.g., pre-uploaded files)
Pre-upload Media (if any)
When scheduling with media, user uploads file(s) to your server or S3 bucket.
Backend:
Validates media
Stores
media_urlsin DB(Optional) pre-processes to match Twitter’s media requirements
3. Enqueue tweet_id Into Time-Partitioned Job Queue
A time-partitioned job queue is a design pattern where jobs (in our case, scheduled tweets) are grouped and organized based on the time they are supposed to be executed - typically by minute or second.
Here’s the core idea:
Tweets are grouped into queues per minute:
Key:
queue:scheduled:2025-05-24T12:45Value: Sorted Set of tweet IDs
Example (Redis Sorted Set):
ZADD queue:scheduled:2025-05-24T12:45 1716545100 tweet_idWhere 1716545100 = UNIX timestamp of 12:45 PM.
We may use Kafka, Redis, or DynamoDB TTL+streams depending on infra, but the goal is:
"At every minute, there’s a queue of tweets due for that exact minute."
Here we are storing only tweet id instead of entire tweet : Storing only the tweet ID is more scalable, supports live edits, and is the industry standard for large-scale schedulers.
Use full-payload queuing only in simpler systems where real-time editing or resource use isn't a concern.
4. Time-Tick Dispatcher (Scheduler)
A scheduler service runs every second (or finer resolution).
It does:
Fetch keys like
queue:scheduled:2025-05-24T12:45Pull all jobs due in that minute (or second).
Push them to internal task queues or distribute them to workers.
This avoids scanning the entire DB
System only looks at queues for now or the next N seconds
5. Distributed Workers (Posting Engine)
Let’s say we have 100 worker nodes running.
Each worker:
Pulls jobs for
12:45 PM.Picks a
tweet_idfrom internal job queueFetches tweet metadata from DB:
SELECT * FROM scheduled_tweets WHERE tweet_id = :id AND status = 'scheduled';Validates tweet is still valid (not cancelled/edited)
If media is attached:
Uploads media to Twitter using:
POST https://upload.twitter.com/1.1/media/upload.jsonStores
media_idsin DB for later reuseCalls Twitter API with stored user access token:
POST https://api.twitter.com/2/tweets
Authorization: Bearer <user_access_token>
Body: { text: "Hello World", media: {...} }Marks tweet as
postedin DB.If API call fails:
Retry with exponential backoff
Move to DLQ after N attempts
Worker pool can scale horizontally with traffic
Ensures only valid tweets are dispatched (still stored in DB if dropped mid-queue)
6. Retry & Dead Letter Logic
Retries happen with delayed job queues or backoff strategies.
For temporary API failures (5xx), wait and retry.
After max retries, move to DLQ queue:failed and mark in DB:
UPDATE scheduled_tweets SET status='failed', retry_count=3 WHERE tweet_id = ...Admins/devs can analyze or replay from DLQ.
7. Concurrency & Locking (Avoid Duplicate Posts)
Redis or Zookeeper is used to ensure only one worker processes a tweet.
Can use:
SETNX lock:tweet:<id>in Redis with expiryKafka partition keys (to ensure message ordering + single consumer)
Database row locks (if all else fails)
8. Edits/Deletes Before Posting
If a user:
Edits: Update content/media in DB, no need to touch queue
Cancels: Just mark
status = 'cancelled', worker will skip
Clean, atomic model
Always posts latest version from DB
9. Scale Handling
Let’s say at 12:45 PM:
15,000 tweets need to go out.
We partition the job queue by minute →
queue:scheduled:12:45.Workers are split across tweet ID shards:
Worker A: IDs ending in 0–3
Worker B: 4–6
Worker C: 7–9
This spreads load evenly.
We can also:
Add latency-based scaling (more tweets → more workers).
Prioritize high-volume windows (e.g., prime hours).
10. Monitoring & Metrics
Track:
Tweets per minute
Success/failure count
Average delay between scheduled_time and posted_time
DLQ volume
Twitter API error rates
Alert on:
Posting latency > 10s
DLQ size growing
Worker lag
Add Support for Other Platforms
By abstracting the platform-specific API handling into modular workers (e.g., TwitterWorker, LinkedInWorker, etc.), you can reuse the core pipeline (scheduling, storage, queueing) while only adding a new “poster module.”
A Tweet Scheduler isn’t just a background cron job - it’s a real-time system with strict accuracy, concurrency, and fault-tolerance requirements.
By partitioning jobs, using distributed workers, and designing around Twitter API constraints, you can build a system that scales with millions of users without missing a beat.
Really great post! I liked how clearly you explained everything. Looking forward to more content like this