
How to Handle 10,000 Concurrent Users
Every system eventually hits this moment.


One quiet Friday you ship your new app, close the laptop, and head out for coffee. Suddenly a celebrity tweets your link. In ten minutes 10,000 people smash the Sign Up button - and your single‑box server starts doing its best impression of a pressure cooker.
At first, it sounds like a capacity question.
In reality, it’s a systems thinking question.
Let’s start with the approaches that seem correct - and why they fail.
First Attempts (and Why They Break)
Attempt 1: Just Add More Servers
The most common instinct. Traffic increases → add more app servers → problem solved.
Why it feels right:
Horizontal scaling is industry standard
Cloud makes it easy
Works at low to medium traffic
Why it fails:
Shared bottlenecks don’t scale automatically
Database, cache, auth service, third-party APIs all become choke points
One slow downstream service can stall thousands of requests
You scaled the frontend, not the system.
Lesson :Concurrency pressure usually breaks dependencies, not CPU.
Attempt 2: Increase Thread Pool Size
Another classic fix. “Let’s increase the thread pool from 200 to 2,000.”
Why it feels right:
More threads = more users handled
Easy config change
Looks like progress
Why it fails:
Threads consume memory and context-switching time
CPU spends more time scheduling than doing work
Latency gets worse, not better
JVM / runtime starts thrashing
Concurrency is not free just because threads exist.
Lesson : More threads don’t mean more throughput.
Attempt 3: Cache Everything
Okay, let’s cache aggressively. Cache DB responses, API calls, user sessions.
Why it feels right:
Reduces load
Improves latency
Caching works - until it doesn’t
Why it fails:
Cache stampedes under concurrent misses
Hot keys get hammered
Cache invalidation logic becomes fragile
Memory pressure increases fast
Caching helps load, but it doesn’t control concurrency.
Lesson : Cache reduces work, it doesn’t manage access.
Attempt 4: Let Requests Queue Up
Another tempting idea: “If users come faster than we can handle, let them wait.”
Why it feels right:
No requests dropped
Everything is eventually processed
Why it fails:
Queues grow without bound
Latency explodes
Timeouts cascade across services
Users retry → doubling traffic
Unbounded queues turn traffic spikes into outages.
The Real Problem
10,000 concurrent users is not about users.
It’s about how many things your system can do at the same time without stepping on itself.
The real questions are:
Which operations are blocking?
Which resources are shared?
Which paths must be fast, and which can be delayed?
Once you answer those, the solution becomes clearer.
Lets see step by step how to build such system
Related [Before reading further]
This article scratched the surface. The real interview goes 10 levels deeper.
How do you handle hot partitions?
What if the cache goes down during a spike?
How do you avoid counting the same view twice?
I’ve written an ebook that prepares you for all of it.
35 real problems. The patterns that solve them. The follow-ups you’ll actually face. The principles behind solving problems at scale, not just the final answers.
The Correct Architecture
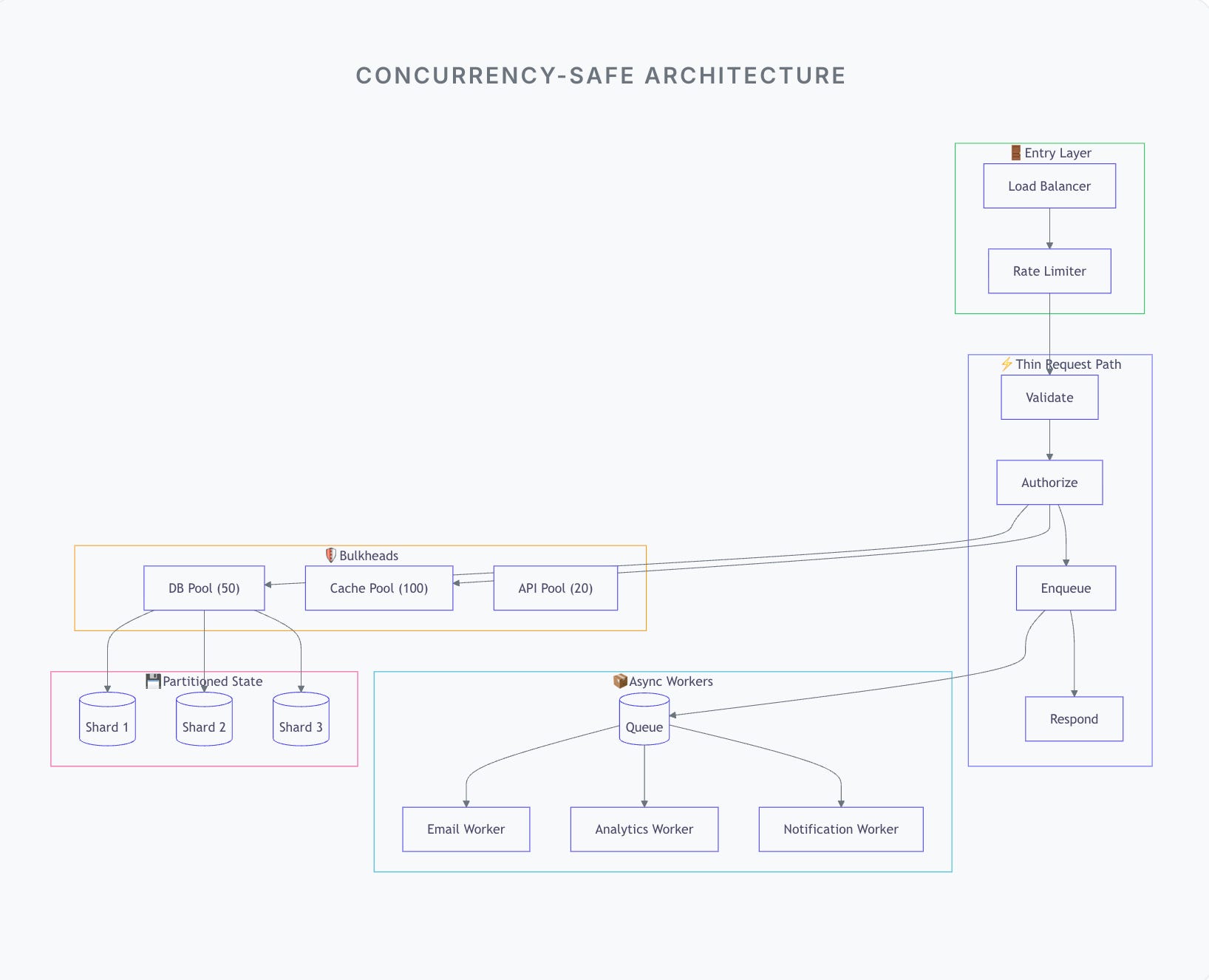
1. Make the Request Path Thin
The request thread should do as little as possible.
Validate input
Authorize
Enqueue work
Return response
Anything slow or non-critical moves out of band.
Concurrency survives when requests finish fast.
2. Control Concurrency Explicitly
Instead of letting everything run freely:
Limit concurrent DB calls
Limit outbound API calls
Apply bulkheads per dependency
When limits are hit:
Fail fast
Return degraded responses
Don’t let pressure spread
This protects the system from itself.
3. Separate Immediate Work from Deferred Work
Not everything needs to happen now.
Emails
Notifications
Analytics
Logging
Recommendations
Push these to queues and process asynchronously.
Users care about response time, not background perfection.
4. Scale State, Not Just Compute
Stateless app servers scale easily. State doesn’t.
Partition data
Reduce shared locks
Avoid global coordination
Prefer per-user or per-shard isolation
Concurrency collapses when everyone waits on the same thing.
5. Apply Backpressure Early
When the system is under stress:
Reject requests early
Return 429s
Degrade features
Shed load intentionally
A fast rejection is better than a slow failure.
Why This Works
This approach works because it accepts a hard truth:
You can’t handle infinite concurrency - but you can control it.
Requests finish quickly
Slow work happens elsewhere
Failures stay contained
Traffic spikes don’t turn into outages
10,000 concurrent users stop being scary. They become just another number.
Interview Pivot
If asked:
“How would you handle 10,000 concurrent users?”
“I’d keep the request path thin, control concurrency to shared dependencies with bulkheads, move slow work async, apply backpressure early, and scale state carefully.
That way concurrency increases without collapsing latency.”
That answer shows you understand system behavior, not just scaling slogans.
What’s Next?
Real systems bring follow-ups:
What happens when one dependency slows down?
How do you prevent retry storms?
How do you degrade gracefully?
How do you observe concurrency bottlenecks?
We’ll dive deeper into these kinds of follow-ups in upcoming articles (or in ebook)- subscribe if you want more.
Thanks for reading. See you in next post.
Nice article 👍🏻