
How to Log 1M Events/Sec Without Slowing Down Your System
Why Logging Isn’t as Simple as It Looks

Every modern system - whether it’s a fintech app processing payments, an ad-tech platform tracking impressions, or a multiplayer game updating player actions - relies on one silent backbone:
Logs
They’re the breadcrumbs of truth.
A debit failure in banking
A player teleporting in a game
A “Buy Now” button click in e-commerce
A leaderboard refresh in a fantasy sports app
Individually, they look tiny.
Collectively, they become millions per second.
The issue is
Logging feels trivial when traffic is small.
At scale, logging becomes one of the most expensive operations in your system.
Because logging is not “just write a line.”
It is I/O + storage + latency + durability + retention + indexing + retrieval + analytics.
And once your traffic crosses a certain threshold, the naïve approach falls apart.
Let’s break down why logging at massive scale is hard, and how to do it right.
First Attempt: Log Directly Inside App Code
Most beginners start here:
log.info(”User “ + userId + “ clicked Buy Now”);Why it feels right:
Easy to write
Works in dev
Shows logs instantly
Why it fails at scale:
Logging is blocking IO
Every write competes with CPU cycles meant for business logic
If logs go to disk → disk bandwidth becomes bottleneck
If logs go to external system → network latency kills throughput
If logs are synchronous → one slow write pauses the entire request
At 1M events/sec, this model collapses.
Even a 1ms logging cost means:
1,000,000 events × 1ms = 1,000,000ms = 1000 seconds latency → impossible.Direct synchronous logging couples application performance with logging performance and that’s dangerous.
Attempt 2: Batch Logs and Write Periodically
Okay, so developers try batching:
buffer.append(event)
if buffer.size >= 1000:
writeToDisk(buffer)
buffer.clear()Why it feels right:
Fewer writes = fewer syscalls
Better throughput
Common in logging libraries like Logback, Bunyan, Serilog etc.
Why it still breaks:
If your process crashes → buffered logs vanish
If bursts exceed buffer capacity → logs drop
Writing periodically still requires locking, causing contention across threads
If storage slows down, buffers back up → memory explodes
At 1M/sec, even buffering isn’t enough.
Batching helps, but doesn’t decouple logging from request handling.
┌──────────────────────┐
│ Application Code │
└───────────┬──────────┘
│
│
▼
(In-memory buffer)
┌───────────────┐
│ Log Buffer │
│ (Batch size) │
└───────┬───────┘
│
(flush every X events/time)
▼
┌─────────────────┐
│ Disk/DB/HTTP │
└─────────────────┘Attempt 3: Log to Database
Idea: store logs in SQL or NoSQL since it’s durable and queryable.
Sounds nice.
Until things break:
DB inserts become bottleneck
Locks + indexes kill write throughput
Querying logs affects real app data
Storage cost skyrockets
Retention becomes a nightmare
A typical database can handle:
MySQL: ~10k writes/sec (with tuning)
MongoDB: 50k–200k writes/sec (clustered)
Cassandra: high write throughput but still expensive at scale
1M/sec destroys it - financially and operationally.
Databases are for structured data, not firehose-scale telemetry.
Attempt 4: Send Logs Directly to Elasticsearch / OpenSearch
This is where many companies fail.
Elasticsearch gives:
Searchability
Visual dashboards
Indexing
Alerting
Feels perfect.
Until indexing overhead hits.
Indexing every event means:
Tokenization
Sharding
Replication
Compression
Persistence
Even a large ES/OpenSearch cluster struggles beyond 200k–300k events/sec without: massive hardware , lots of tuning and big maintenance overhead
Lesson:
Elasticsearch/OpenSearch is great for querying logs - not ingesting raw firehose scale directly from apps.
Related [Before reading further]
This article scratched the surface. The real interview goes 10 levels deeper.
How do you handle hot partitions?
What if the cache goes down during a spike?
How do you avoid counting the same view twice?
I’ve written an ebook that prepares you for all of it.
35 real problems. The patterns that solve them. The follow-ups you’ll actually face. The principles behind solving problems at scale, not just the final answers.
The Scalable Architecture
To log 1M+ events/sec without hurting latency, you need one principle:
Logging must be asynchronous, streamed, and decoupled from the application.
Here’s the architecture that works:

1) Application Layer: Non-Blocking Logging
Use async log appenders
Logs go to in-memory ring buffers
Logging never blocks request path
Libraries:
Java: Logback AsyncAppender, Disruptor logging
Go: Zerolog
Node: Pino
Rust: Tracing layer
No waiting. No flushing. No disk writes on main thread.
2) Queue or Stream: The Shock Absorber
This absorbs bursts and smooths throughput.
Use:
Kafka
Pulsar
Kinesis
Redpanda
Google Pub/Sub
Benefits:
Producers write at memory speed
Consumers scale independently
Backpressure is handled automatically
Replay and retention available
Kafka alone can handle millions/sec with proper partitions.
3) Storage Layer: Hot + Warm + Cold
Different logs need different storage.
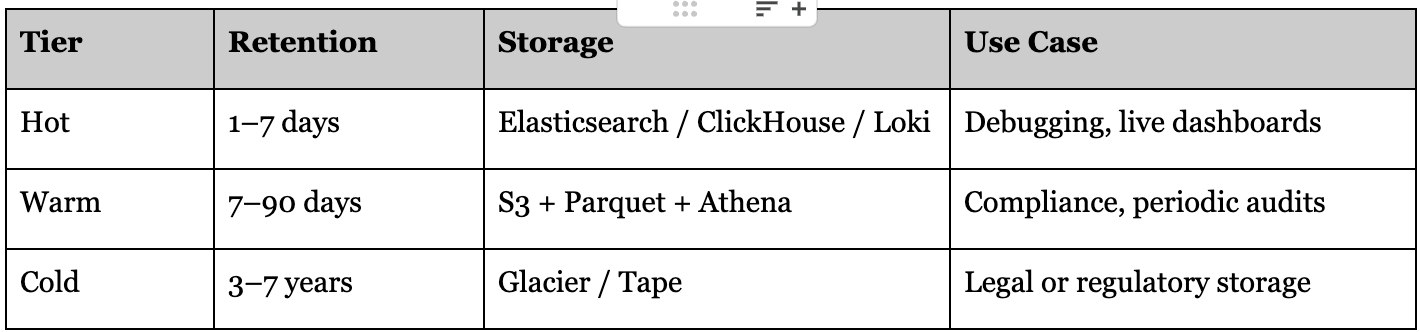
You don’t index everything - you promote only what’s useful.
4) Observability: Metrics Over Logs (When Possible)
Not every event needs a log line.
Sometimes counters, histograms, and traces are better.
Use:
Prometheus
OpenTelemetry
Grafana Tempo
The mindset:
“Log what matters. Aggregate what repeats.”
Why This Architecture Works
This architecture works because logging no longer stands in the way of real work.
The app writes once and moves on - no waiting, no blocking. As traffic grows, you don’t fight the system, you just add more consumers and partitions.
Storage becomes smart instead of expensive: fast where needed, cheap everywhere else.
Even if parts fail, the system keeps absorbing events without dropping them. In the end, logs flow like a river - not a traffic jam.
Interview Answer
If asked:
How would you log 1M events/sec?
You respond:
I wouldn’t log directly. I’d log asynchronously, push events into an in-memory buffer, stream them through Kafka, and then store them in tiers: hot for recent searchable data, warm for analytics, and cold for long retention.
That way logging never slows requests, stays durable, and scales without rewriting the system.
Potential Follow Ups
How to avoid log duplication?
How to detect ingestion lag/remove backpressure?
What if Kafka cluster goes down?
How to avoid logging sensitive/PII data?
We’ll dive deeper into these kinds of follow-ups in upcoming articles - subscribe if you want more.
Thanks for reading. See you in next post.
Nice article.
Thanks for the deep dive. One approach I have seen systems take is to make the asyn-logger write to a short lived file on disk (5 mins or 1hr) and let a daemon running (independent from the application) on the same instance to take care of flushing those logs to the stream/queue system over network. This way (1) company can have a centralized system decoupled from application's language etc. for publish logs (2) handle Kafka/Kinesis failure using retry without bothering the application (3) application crashes won't affect logging (esp info needed to debug the crash), daemon would continue to publish as long as instance is up (4) allow batching to avoid too many network calls.