
How Would You Compute Trending Posts at Millions of Events per Second?
Computing "Trending Posts" Is Harder Than It Looks


Every social platform has it. A Trending section.
The posts everyone seems to be talking about right now - not yesterday, not last week, but this minute.
At first glance, it sounds easy. Just count likes and sort, right?
That illusion lasts until traffic grows, events start arriving out of order, and one viral post suddenly floods your system. What felt like a simple ranking problem quickly turns into a real-time data challenge.
In This Chapter
The solutions that look correct but break at scale
Why “trending” is not a batch problem
How real systems compute it continuously using streaming data
We will solve it with first-principles thinking.
First Attempts (and Why They Break)
Attempt 1: Recompute Everything Every Minute
The most obvious idea is this:
Every minute, scan all recent likes, comments, shares, and views
Group them by post
Sort by count
Pick the top 10
Simple SQL or Spark job. Done.
Why it feels right:
Easy to reason about
Works fine when you have 10k posts
“Trending every minute” sounds like a batch problem
Why it fails:
You’re reprocessing the same data again and again
At scale, each minute means scanning millions of events
Latency creeps up → your “every minute” job takes longer than a minute
Spikes (viral posts) make jobs miss their SLA
What looked like a clean batch job quietly turns into a runaway compute bill.
Lesson : Recomputing from scratch doesn’t scale with velocity.
Attempt 2: Maintain Counters in the Database
Okay, let’s be smarter.
Whenever a user likes or comments on a post: Increment a counter in the posts table. Use that counter to decide what’s trending.
Why it feels right:
Constant-time updates
Data is always “fresh”
Easy queries like
ORDER BY score DESC
Why it fails:
High write contention on hot posts
Viral posts become bottlenecks
Locks, retries, and replication lag start showing up
Your primary DB is now handling analytics traffic
Suddenly, your transactional database is doing real-time ranking. That never ends well.
Lesson : Databases are great at state, not high-frequency event aggregation.
Attempt 3: Cache Trending Posts in Redis
Fine. Move fast stuff to Redis.
Increment counters in Redis
Every minute, read top keys
Redis is fast, right?
Why it feels right:
In-memory speed
No DB locks
Widely used pattern
What’s the problem:
Redis becomes a single hot spot
You lose ordering guarantees under heavy concurrency
Crash or restart = counters gone (unless heavily persisted)
Cross-region or multi-shard ranking gets messy
Redis helps performance, but it doesn’t solve time-windowed aggregation cleanly.
Lesson : Speed alone doesn’t solve correctness at scale.
Attempt 4: Trigger Jobs with Cron
Another classic move:
Run a cron job every minute
Compute trending posts for the last 60 seconds
Publish the result
Why it feels right:
Simple mental model
Clear time boundaries
Easy to debug
What’s the issue:
All computation spikes at the same second
Late events get dropped or miscounted
Real-time systems don’t respect clock boundaries
Users see inconsistent “trending” lists
Trending is a flowing signal, not a punctual snapshot.
Lesson : Time-based cron jobs don’t mix well with real-time streams.
Attempt 5: “Just Use Machine Learning”
Someone always suggests this. “Why not train a model to predict trending posts?”
Why it feels right:
Sounds sophisticated
Great for long-term ranking
Why it fails (for this problem):
ML still needs clean, real-time features
You still haven’t solved streaming aggregation
Latency requirements make inference tricky
Overkill for minute-level trends
ML improves ranking. It doesn’t replace real-time computation.
Lesson : Intelligence doesn’t fix broken pipelines.
The Pattern Emerging
All these approaches fail for the same reason:
They treat trending as a static calculation.
In reality, trending is a moving window over a live stream of events.
To solve it properly, we need to stop thinking in rows and start thinking in flows.
The Right Way to Think About Trending
Once you step back, the mistake in all the earlier attempts becomes obvious.
Trending is not a number. It’s a signal changing over time.
A post doesn’t become trending because it crossed a fixed count. It becomes trending because activity around it is rising faster than others right now.
That immediately tells us two things:
We must process events as they happen
We must reason in sliding time windows, not batches or cron jobs
This is a streaming problem, not a database one.
The Mental Model Shift
Instead of asking:
“Every minute, what are the top posts?”
We ask:
“As events flow in, how does each post’s momentum change?”
Once you adopt this mindset, the architecture almost designs itself.
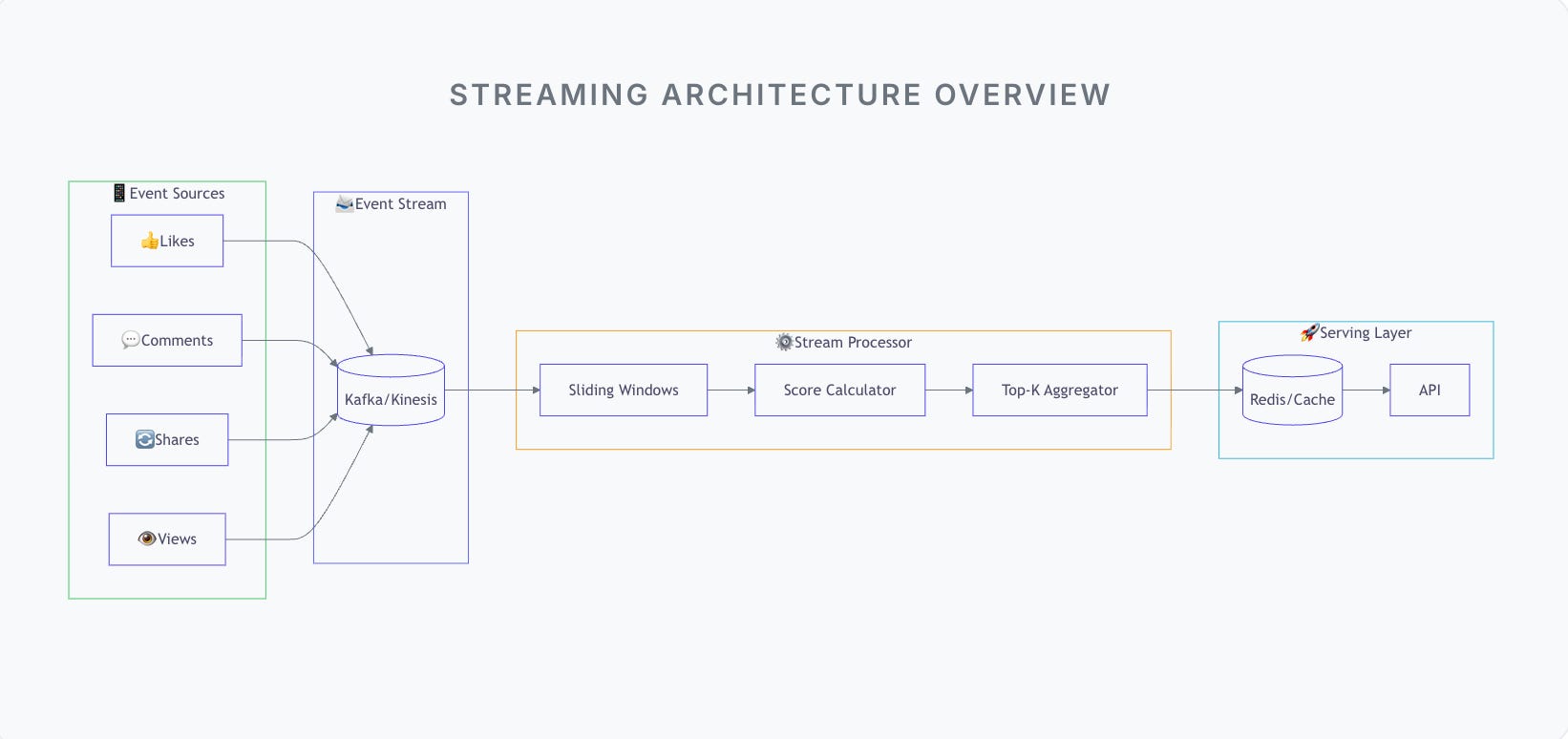
The Architecture: Step by Step
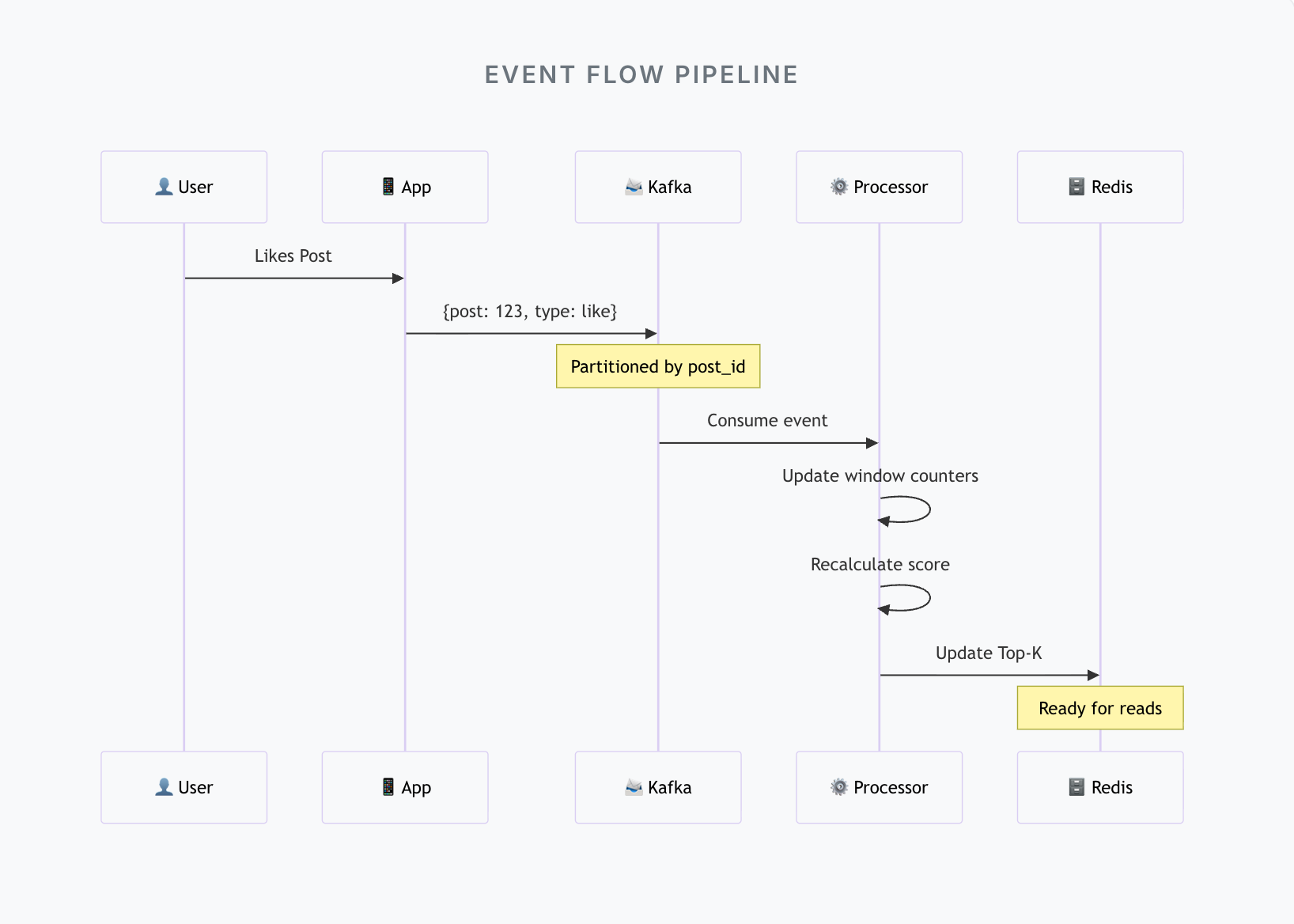
Step 1: Treat Every Interaction as an Event
Likes, comments, shares, views - they are all signals. Each interaction becomes a small event:
{
"post_id": "abc123",
"event_type": "like",
"timestamp": 1702999200
}Nothing is aggregated yet. Nothing is ranked yet. We simply emit events and move on.
This keeps the write path extremely fast and lets the system absorb sudden spikes when something goes viral.
Step 2: Stream, Don’t Store First
These events flow into a stream - Kafka, Pulsar, Kinesis, Pub/Sub.
Why a stream? Because streams:
Preserve order within partitions
Handle burst traffic naturally
Allow multiple consumers to compute different views
At this point, the system isn’t “computing trending” yet. It’s just recording reality as it unfolds.
Step 3: Compute Trends Using Sliding Windows
Now comes the core idea.
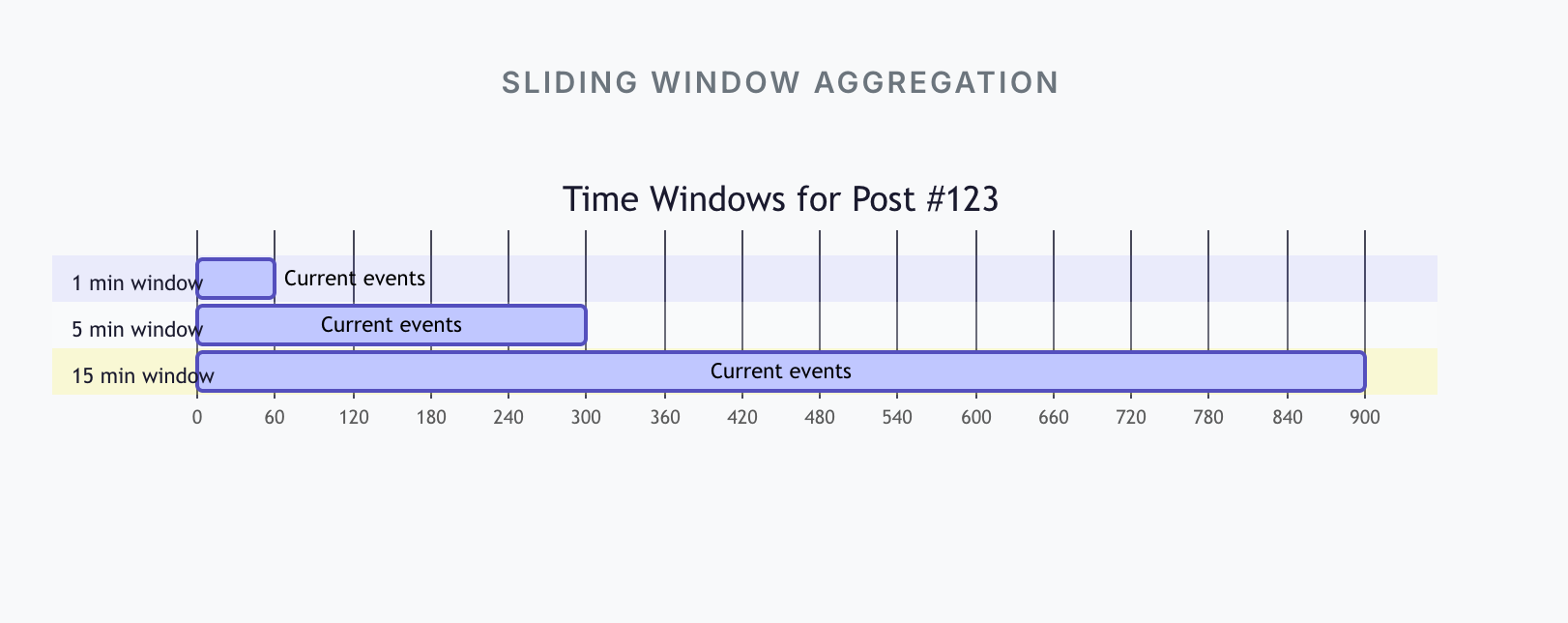
Instead of recomputing everything every minute, we maintain rolling windows:
Last 1 minute
Last 5 minutes
Last 15 minutes
As events flow in, stream processors continuously update counters per post per window.
This is not batch. This is incremental math.
When a new like arrives:
Add +1 to that post’s current window
Expire events that fall out of the window
Update the score instantly
No rescans. No cron jobs. No waiting.
Trending becomes a continuously updated result.
Step 4: Separate Scoring from Ranking
Raw counts alone don’t tell the full story.
A post with 10 likes in 1 minute might be more interesting than one with 1,000 likes over a day.
So instead of just counting, we compute a score:
Weight recent events higher than older ones
Give comments more weight than likes
Normalize by post age
This scoring logic lives inside the stream processor.
The output is simple:
{
"post_id": "abc123",
"trend_score": 847.5,
"window": "5min"
}The heavy thinking happens once, in the stream - not on every read.
Step 5: Maintain a Live Top-K Structure
From these scores, we maintain a Top-K list (say top 100 posts per region or category).
This structure updates incrementally:
When a score changes, we adjust its position
No full sorting required
No global locks
The result is always ready.
When the UI asks for “trending posts”, it’s a simple read - not a computation.
Step 6: Serve Reads Without Touching the Stream
The final trending list is pushed to a fast store:
Redis
DynamoDB
In-memory cache
Reads are cheap. Writes are controlled. The stream keeps flowing independently.
If the UI goes down, streaming continues. If the stream lags, the UI still serves the last known good state.
Failures don’t cascade.
Why This Works (At Scale)
This architecture works because nothing waits.
Events flow in once
Computation happens incrementally
Ranking updates continuously
Reads never trigger heavy work
You’re no longer fighting time or traffic spikes.
Trending stops being a periodic job and becomes a living signal.
Interview Pivot (How to Explain It)
If someone asks:
“How would you compute trending posts every minute?”
“I wouldn’t recompute every minute. I’d treat user interactions as a stream, aggregate them in sliding windows, compute a rolling trend score per post, and maintain a live top-K list.
The UI simply reads the latest result, while the stream updates continuously in the background.”
That answer shows you understand data flow, not just data storage.
What’s Next?
Trending isn’t something you calculate on a schedule. It’s something you observe as it emerges.
This design opens the door to deeper questions:
How do you handle late or out-of-order events?
How do you avoid one viral post dominating forever?
How do you scale this across regions?
How do you debug wrong trending results?
The key insight: Trending isn’t about counting - it’s about capturing momentum. The systems that get this right don’t fight the stream of events. They ride it.
Think in flows, not snapshots. That’s how real-time systems scale.
Related
This article scratched the surface. The real interview goes 10 levels deeper.
How do you handle hot partitions?
What if the cache goes down during a spike?
How do you avoid counting the same view twice?
I've written an ebook that prepares you for all of it.
35 real problems. The patterns that solve them. The follow-ups you'll actually face. The principles behind solving problems at scale, not just the final answers.
Thanks for reading. See you in next post.
The shift from "recompute every minute" to"observe momentum as it emerges" really captures the fundamental mindset change. Most people get stuck treating this as a database query problem when it's actually a flow problem. I ran into this exact issue last year on a project where we initially tried Redis counters and hit the hot partition bottleneck you described, switching to a sliding window with Kafka made the difference but the toughest part was handling late arrivals without doublecounting or introducing crazy lag. How do you typically balance window size vs accuracy when events showup out of order?