
YouTube System Design from First Principles
Explained Like You’re 5, But Smarter

We want to let users upload a video and let millions of other users watch it smoothly.
That sounds simple, but videos are huge (hundreds of MBs), networks are unreliable, and viewers expect instant playback.
So our design has to solve:
Storing large video files safely.
Converting them so they play well on all devices.
Delivering them fast worldwide.
Scaling as traffic grows from 10 users to millions.
Minimum Viable Product (MVP)
Let’s start with the simplest working version.
Components
Client Upload → Object Storage
Instead of sending a huge file through our server, the client uploads directly to Object Storage (like Amazon S3 or Google Cloud Storage).
Why? Because it’s built to store huge files, automatically replicated, and cheap.
App Server (Metadata)
Handles small data: title, description, user info, publish status.
Stores this in a Relational Database (Postgres/MySQL).
Transcoding Service (Video Processor)
Takes the uploaded raw video and converts it into multiple formats (240p, 480p, 720p).
Why? Different devices and network speeds → different quality needed.
CDN (Content Delivery Network)
A global network of servers that caches video segments close to users.
Why? Without CDN, every play would hit our storage directly → slow and expensive.
Queue (Task Manager)
When a video is uploaded, we push a “transcode this file” job into a queue.
Workers pull jobs one by one → keeps system stable even if thousands of uploads happen.
Database Glimpse
-- Who uploaded what
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(200) UNIQUE
);
-- Core video table
CREATE TABLE videos (
id BIGINT PRIMARY KEY,
owner_id BIGINT REFERENCES users(id),
title VARCHAR(200),
description TEXT,
status VARCHAR(20), -- uploaded, processing, published
created_at TIMESTAMP
);
-- Which renditions exist
CREATE TABLE renditions (
video_id BIGINT REFERENCES videos(id),
quality VARCHAR(10), -- 240p, 480p, 720p
path TEXT, -- storage/CDN path
PRIMARY KEY(video_id, quality)
);
Why This Works (MVP)
Simple: only 5 moving parts.
Resilient: queue prevents overload.
Cost-efficient: CDN cuts bandwidth bills, storage is cheap.
But… it’s limited:
Startup latency (may take 2–3 seconds to buffer).
Limited quality options.
All running in one region → bad for global users.
Scaling Up (When Traffic Grows)
When our MVP gets popular (say, 100k uploads/day, 1M viewers), cracks appear. Let’s evolve step by step.
Playback Experience
Issue: Viewers wait 2–3 seconds before playback begins.
Solution: Preload the first few seconds into the CDN as soon as a video is published. Playback feels instant.
Upgrade: Add higher qualities like 1080p, but only for videos that cross a popularity threshold. This saves storage and processing costs.
Database Load
Issue: With millions of requests, the relational database struggles with queries like trending videos, likes, and search.
Solution:
Add a cache (Redis) for popular data.
Use a search index (Elasticsearch) for fast lookups.
-- Daily view counts (approximate is fine)
CREATE TABLE video_views (
video_id BIGINT REFERENCES videos(id),
day DATE,
approx_count BIGINT,
PRIMARY KEY(video_id, day)
);Exact counters aren’t necessary; eventual consistency is good enough for user experience.
Cost Control
Issue: Storage and bandwidth bills grow rapidly.
Solution:
Move older, rarely watched videos to cold storage.
Use per-title encoding to compress intelligently, cutting bandwidth by 20–40%.
Global Expansion
Issue: A viewer in UK fetching video data from a US server faces high latency.
Solution: Replicate storage across regions and let CDNs serve videos from the nearest origin.
Reliability and Failures
Issue: Transcoding jobs pile up or storage has a temporary outage.
Solution:
Use dead-letter queues to handle failed jobs.
Autoscale worker pools; temporarily skip highest quality and backfill later.
Multi-region storage ensures redundancy.
Lessons from YouTube’s Growth
From a single bucket and database, the system grows into a global platform:
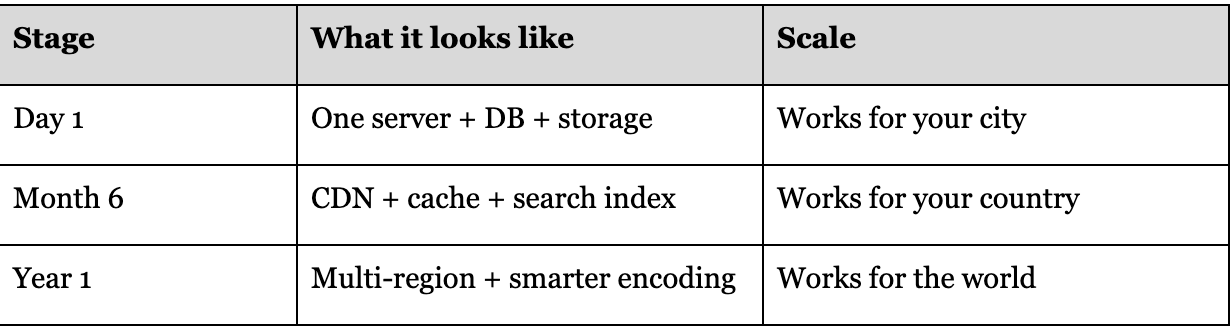
We started with the simplest version of YouTube: a bucket for files, a database for metadata, and a queue for processing. That was enough for the first few thousand users.
But real systems don’t stay small. As traffic grew, new challenges appeared one by one: buffering, database overload, rising costs, global latency, and reliability concerns. Each time, the solution wasn’t magic it was applying first principles:
Keep data close to users.
Optimize for real-world networks.
Spend compute and storage only where it creates visible value.
Design for failure so the system bends instead of breaking.
The end result is what we see today: a system that can absorb millions of uploads and serve billions of daily views without users thinking twice about what happens behind the scenes.
System design isn’t about memorizing complex diagrams it’s about starting with a clear mental model, asking “what must always be true?”, and evolving step by step as scale demands.